
Well, this is my first article so if it sucks tell me...lol!!
Story Time
Well, story time....yaaay!!!
I wanted to learn buffer overflows and binary exploitation and all those asm crap...lol
So I opened up a lotta sites and eventually came across a polytechnic website with pdfs and ppts full of that. It was kind of like a syllabus with notes and all. I was ecstatic and then I figured I will start downloading all of it. But then it was like 22 pdfs and I was not in the mood to click all 22 links so I figured I will just write a python script to do that for me. It was awesome when it worked, didn't think it would...lol!! So don't believe in yourself. Believe in your code!! Just kidding!! Believe in whatever you want to. I don't care.
Step 1: Import the Modules
So this typically parses the webpage and downloads all the pdfs in it. I used BeautifulSoup but you can use mechanize or whatever you want.

Step 2: Input Data
Now you enter your data like your URL(that contains the pdfs) and the download path(where the pdfs will be saved) also I added headers to make it look a bit legit...but you can add yours...it's not really necessary though. Also the BeautifulSoup is to parse the webpage for links

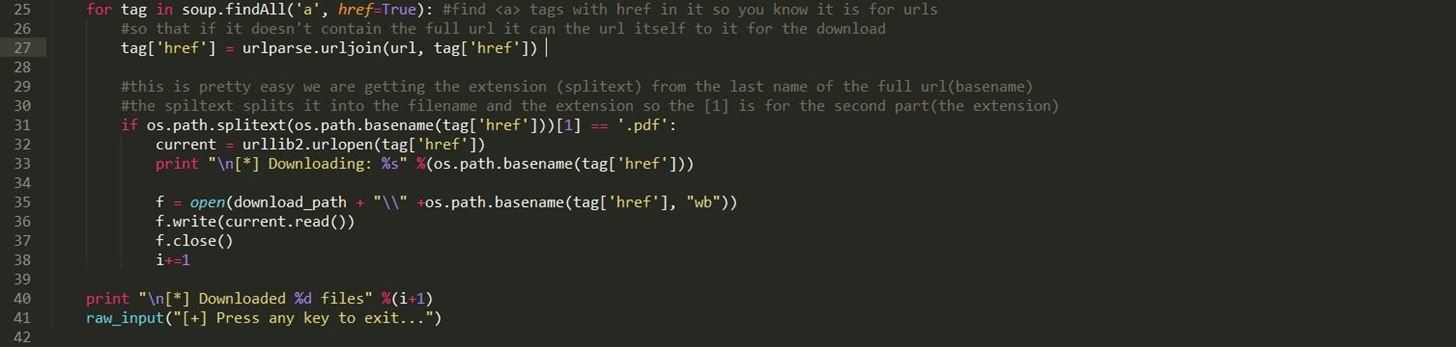
Step 3: The Main Program
This part of the program is where it actually parses the webpage for links and checks if it has a pdf extension and then downloads it. I also added a counter so you know how many pdfs have been downloaded.
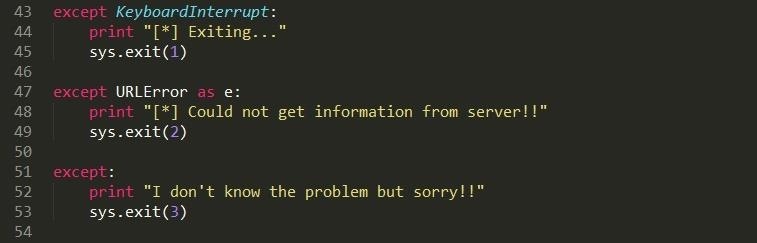
Step 4: Now Just to Take Care of Exceptions
Nothing really to say here..just to make your program pretty..that is crash pretty XD XD
Conclusion
Well, that's it...if you have any questions let me know...I haven't really tested the code because I wanted a clean one. But I copied it from the one that worked so it should...sorry for errors and bad English...thanks for reading to the end and looking at this...also if there are any suggestions or anything to add please let me know...and you can improve it all you want :D But I will like a little credit...I mean who won't...lol
KNOWLEDGE IS FREE!!!!
Just updated your iPhone? You'll find new emoji, enhanced security, podcast transcripts, Apple Cash virtual numbers, and other useful features. There are even new additions hidden within Safari. Find out what's new and changed on your iPhone with the iOS 17.4 update.



















30 Comments
Great article!
Loving the well commented code ;)
Thanks :)
Thanks :D
Good work.
Nice article.
Could you let me know the URL of the website you found with the 22 pdf's please? It would probably come in handy and I can also test this out.
You can test it on any site. I just don't think it is necessary. But since it's no secret and what the hell..why not?! Here you go!! :D
http://security.cs.rpi.edu/courses/binexp-spring2015/
Let me know if there are any errors. so i can correct them :) Thanks!
Sure. No problem at all.
Did it work for you?
I haven't had the chance to try yet. Will pm you when I have ;-).
Ok..thanks
Phoenix750 suggested:
So here:
http://pastebin.com/nRVXgmqF
Thanks
Hey man great article and idea for a script!
I was testing it out and I got the following error:
Traceback (most recent call last):
File "./PdfCrawler.py", line 50, in <module>
except URLError as e:
NameError: name 'URLError' is not defined
It doesn't seem to recognize the URLError exception. Did anyone else got this error? Am I missing some package or something?
thanks
You welcome bro....it is possible you didn't import the urllib2 module..sorry but I can't really help without seeing your script. if you can send like a screenshot of it, that will be very helpful.
Thanks again.
~ManWuzi~
You can edit to :
except urllib2.URLError as e:
print "* Could not get information from server!!"
sys.exit(2)
I have a tiny problem with your code...I guess. It works! However it does not download the entire pdf. For example a PDF is 300 kb large and the script downloads only 135kbs of it. I can't figure out why? :( Any help it's more then welcome. Here is my code: http://pastebin.com/LSDFFUzw
Hi Tibi,
I have gone through your code but unfortunately I'm not really familiar with the requests module. I do think your code looks fine and should work great but from the little I know I think the problem with your code is you only write some part of the files content. In your for loop
for chunk in res.itercontent(999999999):
pdfFile.write(chunk)
I think only the chunk part is written not all of it. I think a solution to your problem might be to use a while loop something like this:
while res.itercontent() not empty():
pdfFile.write(res.itercontent())_
Like I said I am not familiar with the requests module so I can't really help you there but I hope you understand my point.
ManWuzi
Thanks!
I was supposed to iterate through current not res. Res is the first url. It was stuck at finding the equivalent of the your modules because I use python 3.4. Thanks for your code. It works like a charm! Cheers!
Glad you fixed your problem. And thanks.
Hi Manwuzi,
I get problem with this site: https://crypto.stanford.edu/cs155/syllabus.html. Can you improve your code to continue after can not open non-existing file (https://www.cse.psu.edu/~tjaeger/cse443-s12/docs/ch4.pdf
Regards,
Yeah, I took a look at the source code of the webpage and noticed the href tag wasn't written well but you can put the download part of the script in a try except block....
try:
current = urllib2.urlopen(tag'href')
print "\n* Downloading: %s" %(os.path.basename(tag'href'))_
f = open(downloadpath + "\\" +os.path.basename(tag'href', "wb"))
f.write(current.read())
f.close()
i+=1
except:
print "The file %s cannot be downloaded" %os.path.basename(tag'href')
I hope you understand. And I hope this helps you
Thanks for your suggest.
Can you check your script with the URL: http://cseweb.ucsd.edu/classes/su15/cse140-a/syllabus.html. Script will fail when download lec3before.pdf and others next
Regards,
I lost all my files when my PC crashed. and I don't really feel like running it. Sorry . but if you can send your code. I will take a look at it, and let you know of any error..
Poor you :( . I & my friend have fixed the script.
Source code of that page has comment tag errors so that drive the script stop when parse.
Regards,
ok...I'm glad you figured it out...and thanks...sorry if i wasn't much help either
what IDE are you using
I used the normal python IDLE, python is a scripting language so the IDE doesn't really matter. But for the screen captures, i opened the file in Sublime Text. Cos it has beautiful colours :D
How can we download PDF files if there is a login authentication ?
hey i tried the same code but it is not working..
Any help please...
Am just getting I dont know the problem..
I downloaded all the packages..
Is there any problem in entering the download path..
So confused..help would be appreciated..
Thanks..
Hi, I copied your script and tried to run it. When I enter the url, it opens the website in Firefox in a new window. What am I supposed to do next?
I have used your code and I got this error.
surukam@surukam-Lenovo:~/scrapy/newtry$ python myspider.py
File "myspider.py", line 7
from bs4
^
IndentationError: expected an indented block.
I have checked in net and i aligned he code with correct spaces. But its shows same error. Can you help me with this pls..., And I have a doubt. I need to with 2 options.
EX: If a website has 200-300 PDF files in different locations.
1.I have to download all the .pdf files in given URL.
I want to use both option also. If you have any other code for download a specif PDF(search with some keywords) and download that. Have you worked with any other crawling tools.
Share Your Thoughts