


Hey guys, this is my first tutorial, and my first attempt to give back to the Null-Byte and larger Hacker community. Some basic python knowledge is assumed, but not all that necessary; I'll try to make very clear every line that I'm writing.
I intend to have this series chronicle the development of an original python coded Web-Crawler, with the goal in mind of providing small building blocks along the way. As you're reading this, don't view this post as a "how-to" on building some crazy hacker tool, but rather a tutorial on building your own scripting toolkit. I'm going to try and keep these tutorials rather short and generally decently coding heavy, with one project file being loosely developed along the way. Hopefully by the end of this series you won't have my Web-Crawler; you'll instead have your own customized version.
What exactly is a Web-Crawler?
"Web-Crawlers" (also known as "Web-Spiders") are pretty much robots. Their primary objective is information gathering, and once launched, will comb through the internet ideally gathering information for their creators. They do this by scanning individual web pages, parsing the available HTML code, and jumping through the embedded links.
What are they used for?
Google employs it's own Spiders to map out the internet ; in fact every web browser gets its information through these programs. Getting to know which websites are out there and how they're connected is an overwhelming (and still very incomplete) task, so why not design programs to do it?
As a Hacker, you can use these crawlers for a variety of useful or mischievous tasks. Make a worm spread around the web, probe larger website and company systems, whatever you want. In this tutorial, we will be aiming towards making a Spider capable of completely archiving an entire site and its subdirectories, putting all of its information (and vulnerabilities) on your local machine and in your hands.
So let's get started.
First things first, let's create our new project. If you're on linux/Mac, you can make a new file from the command line with the "touch" command. (Note: If you're a Windows user, that's ok too. Whatever operating system you use will be fine, Windows just isn't my strong suit so I won't mention it here) I'm going to name my Web-Crawler here "gopher.py", because why not.
Now fire up your favorite text editor, and let's get to work.
We're going to need to import the urllib2 module for our program to work. urllib2 is a built in python module for Python version 2.7, which means you don't have to download anything online beyond the vanilla language to use it. We utilize some of it's built in functionality like this:
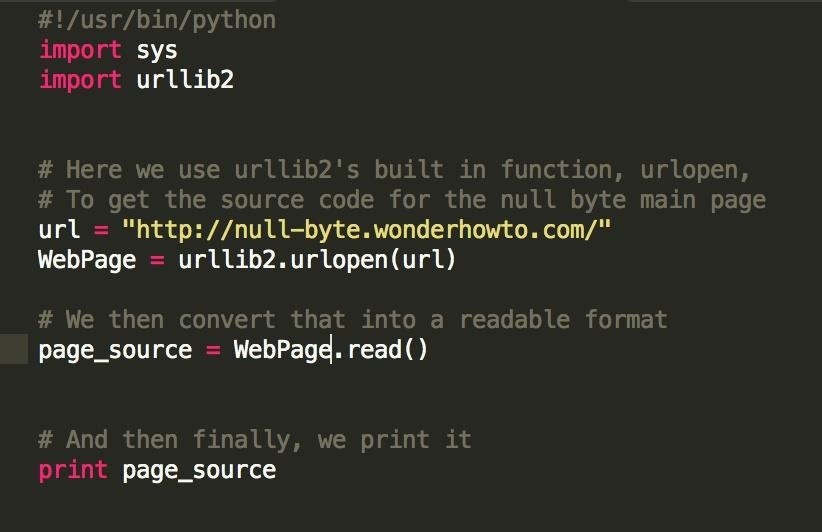
Note: it's good practice to head every python program with the "#!/usr/bin/python" tag.
So we're doing a few things here. First off, we import the urllib2 module, so that we can actually parse html documents. Then, we initialize our WebPage variable as a website object, the result of urllib2.urlopen(). At this point, we have the raw html file stored on our system, and now we can manipulate it. The .read() function will convert this raw file into a readable format, just like we would read any other file on your system.
Finally, we print the result of WebPage.read(), and see the code from our website displayed on our terminal.
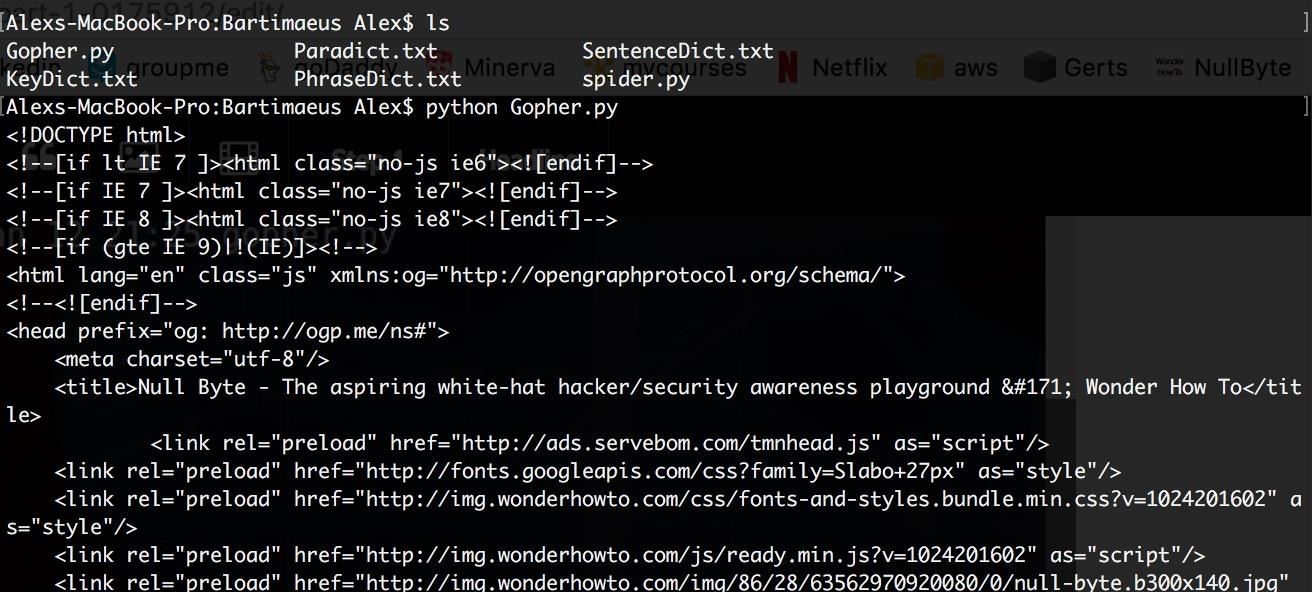
To execute our Python program from the command line, open up your terminal, navigate to the directory where your .py file is, and run the command "python yourProgram.py" (in my case, I ran "python Gopher.py")
If you got everything right, you should see the html code of Null Byte's home page. To verify for yourself, you can navigate there at https://null-byte.wonderhowto.com/ , write clicking on your browser page, and hitting "view page source". The page source should exactly match the output of our program.

Next tutorial we'll actually do something with that html code beyond just print it; even now though, I'm sure you can see some of the potential applications. Soon enough we'll be taking apart this document from inside our python program, and using that information to design our Web-Crawler's search path.
I hope you found this tutorial helpful, tune in next time.


































3 Responses
Nice tutorial ! I hope other tutorials will rock as this one !
Thank you very much, as the first positive feedback I've gotten it means a lot
Check out part 2 here:
https://null-byte.wonderhowto.com/forum/creating-python-web-crawler-part-2-traveling-new-sites-0175928/
Share Your Thoughts