


Welcome back! This is part two of my previous tutorial, https://null-byte.wonderhowto.com/forum/creating-python-web-crawler-part-1-getting-sites-source-code-0175912/
We left off with our web crawler looking like this:
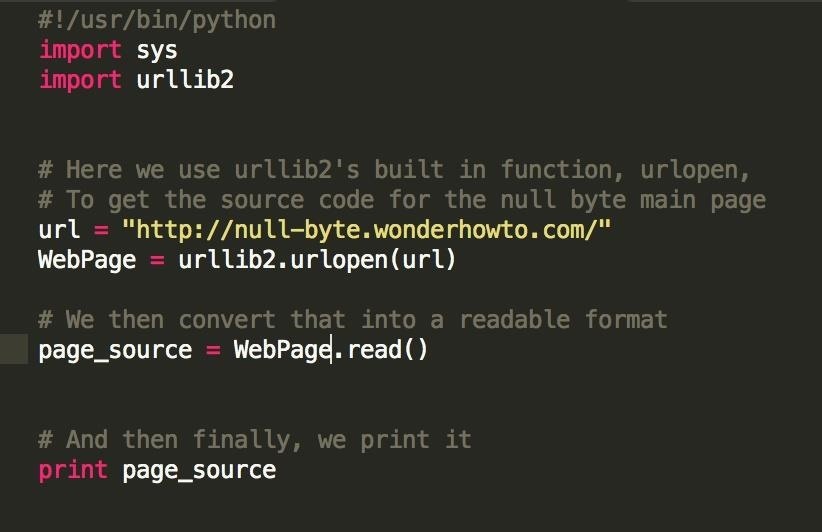
Basically, we found out how to open up a web page in python and download its source-code. Pretty cool, but we haven't really done anything with that source code yet.
What makes a Web-Crawler a real Web-Crawler is it's ability to navigate the web autonomously. What we have done so far is download the contents of one page, but what if we wanted to download the contents of every page out there? We would need a way to allow our program to travel.
To initiate that travel, we first need to split up the page source variable that we created. We can do that like this:
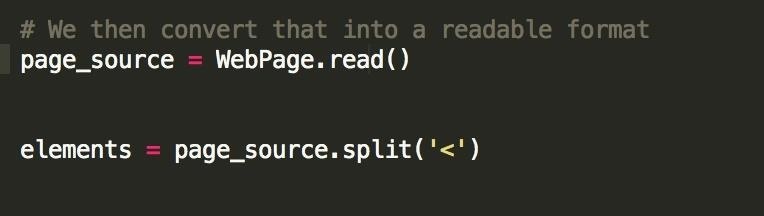
What we're doing here is actually splitting up our html document into specific HTML elements, noted by the '<' tag. Note that in HTML (Hyper-Text-Markup-Language), every new element starts with a '<' character. This can denote a new title element '<h>', a new paragraph element '<p>', a new image element '<img src>', and most importantly!!! a new website link element '<a href>'.
The way we split our HTML doc will generate a list of elements each starting after that '<' character. So, our first task is to actually isolate our links. To do that, we'll need a little bit of string-manipulation magic, something Python is great for (and if you're interested, the scripting language Perl is great for). This stuff is a pain, so I really do recommend you copy exactly what I have below, as it's the process of trial and error.
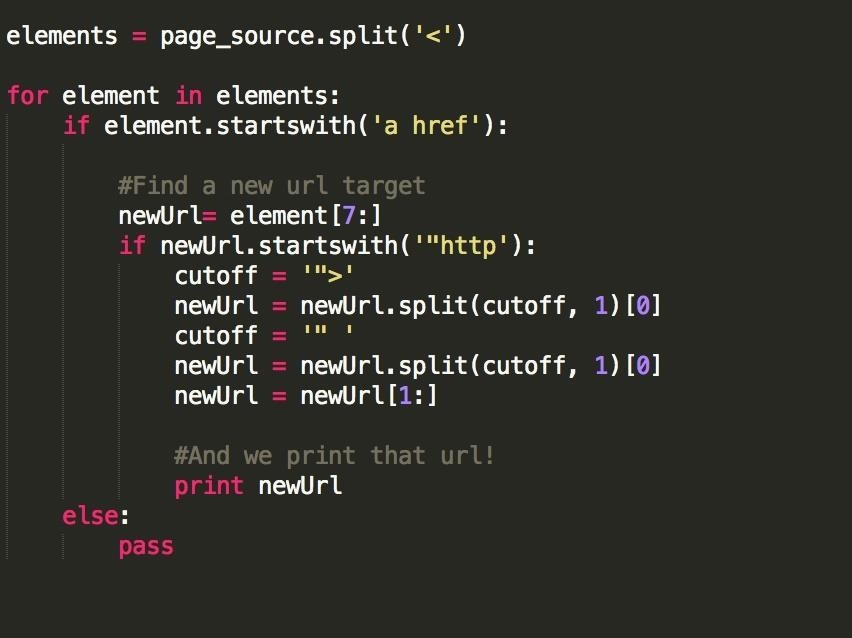
There's a lot going on here, so let's break it down.
- 'for elements in elements' means that for each item in our list of HTML elements, we do something
- 'if element.startswith(' a href ') says that if our current element begins with a link tag (the 'a href), we'll proceed to do the next few lines of code
- 'newURL = element[7:]' cuts off our element to remove the 'a href' tag and spaces; we won't need them anymore.
4.'if newUrl.startswith('"http')' Is just a check to make sure that our element is actually a link (not all elements starting with 'a href' are links, some our image sources or other website things
- The rest is just some string manipulation, to further refine our element into the correct format.
Add in a print statement, and your full program should look like this:
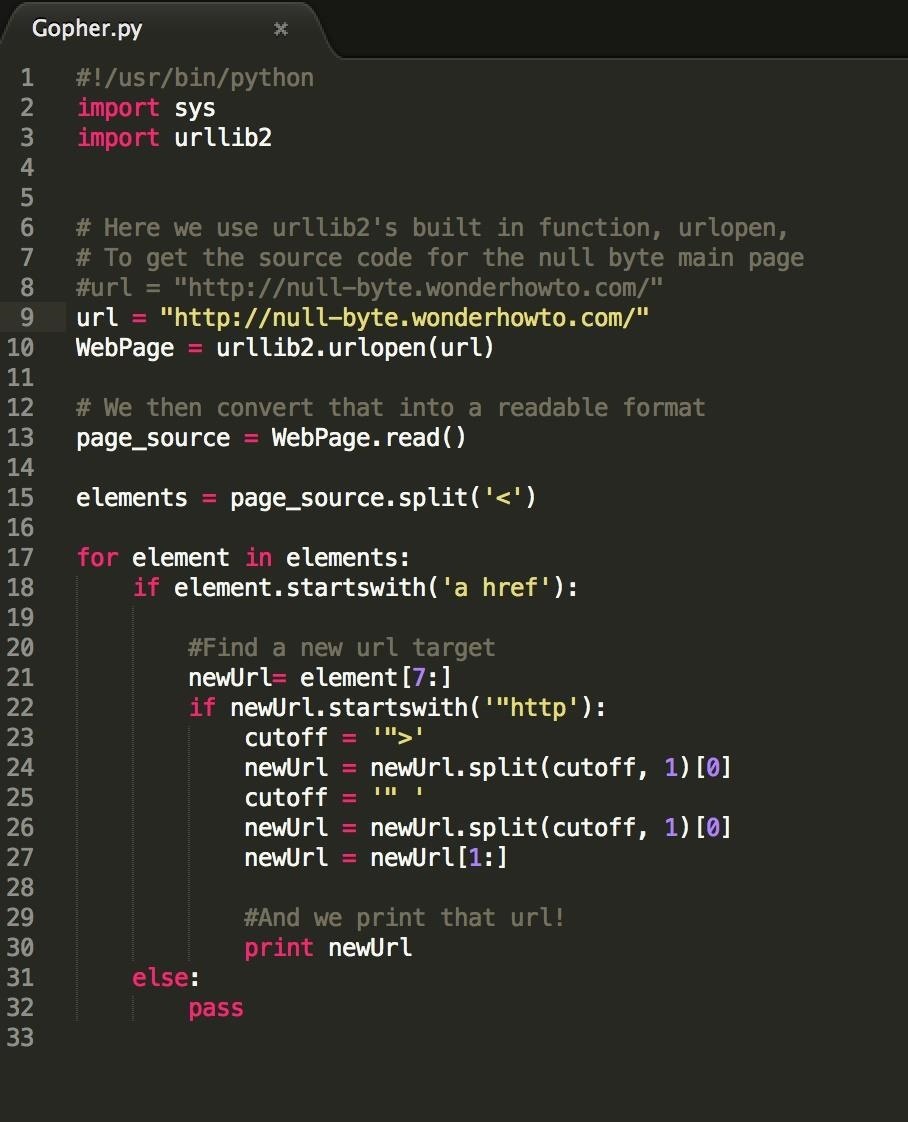
Run your program from the terminal, and we get this output:
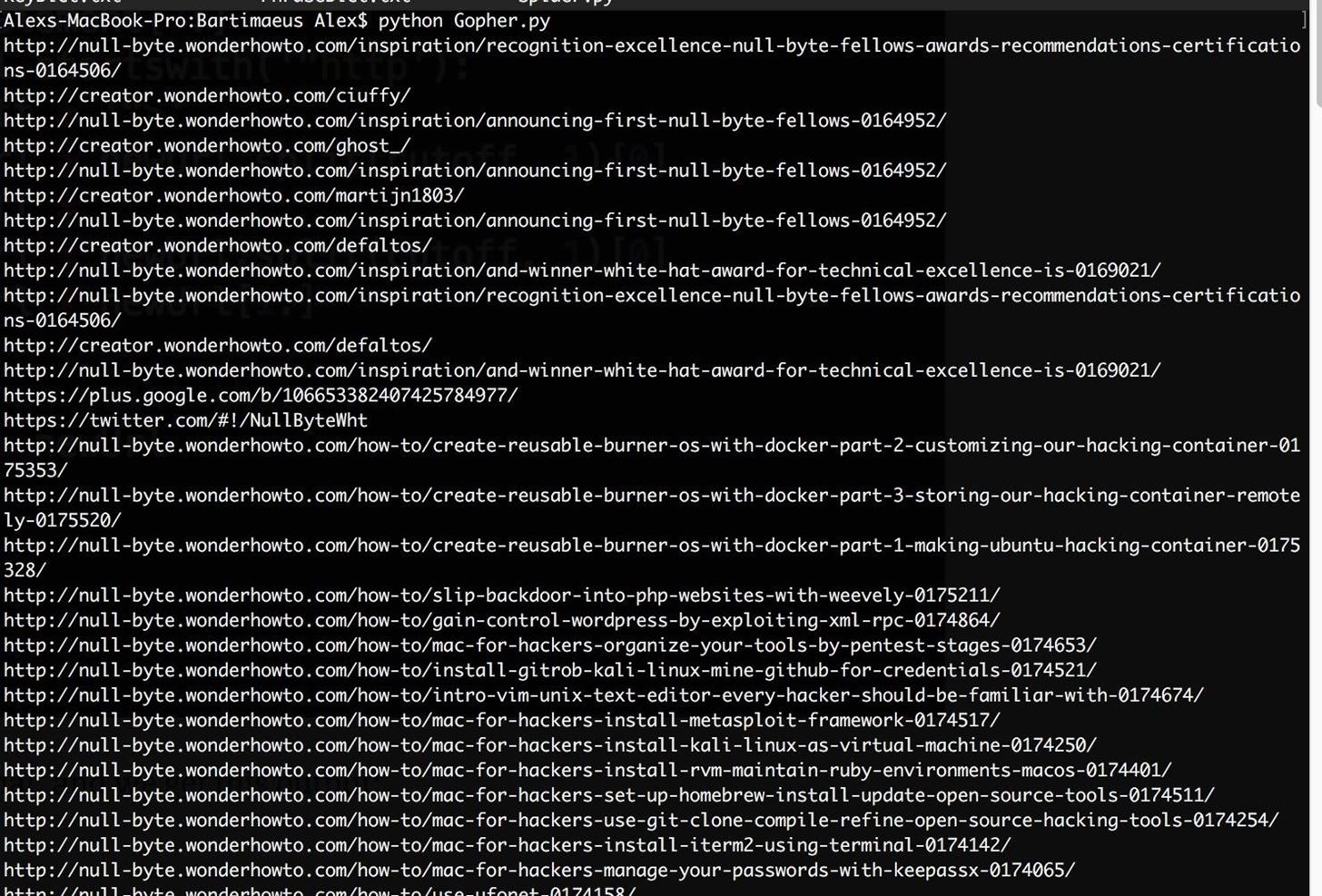
Pretty cool right? Not only have we now opened up a webpage via a python script and downloaded it's contents, but we've refined our search and narrowed our scope to specifically view the embedded links inside.
Now that we have these links, we can start to see how our Web-Crawler can travel. As we'll explore in the next tutorial, we can actually start to replicate our initial process, and see what's inside every one of these html pages as well. Whereas we started by opening one website and viewing its source-code, we now have another 1,000 links to do the same with...
Tune in next time and we'll get our Web-Crawler mobile. I hope you guys enjoyed this tutorial,
Peace out Null-Byte.




































Be the First to Respond
Share Your Thoughts