




Welcome back, my novice hackers!
Before we try to attack a website, it's worthwhile understanding the structure, directories, and files that the website uses. In this way, we can begin to map an attack strategy that will be most effective.
In addition, by knowing what files and directories are there, we may be able to find hidden or confidential directories and files that the webmaster does not think are viewable or accessible by the public. These may become the ultimate target of our efforts.
Directory Traversal Attacks
Directory traversal is a type of attack where we can navigate out of the default or index directory that we land in by default. By navigating to other directories, we may find directories that contain information and files that are thought to be unavailable.
For instance, if we want to get the password hashes on the server, we would need to navigate to /etc/shadow on a Linux or Mac OS X server. We may be able to move to that directory by executing a directory traversal, but before we can do any of this, we need to know the directory structure of the web server.
OWASP, or the Open Web Application Security Project, developed a tool that is excellent for this purpose, named DirBuster. It is basically a brute-force tool to find commonly used directory and file names in web servers.
How DirBuster Works
DirBuster's methods are really quite simple. You point it at a URL and a port (usually port 80 or 443) and then you provide it with a wordlist (it comes with numerous—you only need to select which one you want to use). It then sends HTTP GET requests to the website and listens for the site's response.
If the URL elicits a positive response (in the 200 range), it knows the directory or file exists. If it elicits a "forbidden" request, we can probably surmise that there is a directory or file there and that it is private. This may be a file or directory we want to target in our attack.
HTTP Status Codes
When the Internet was created, the W3C committee designed it to provide numeric code responses to an HTTP request to the website that would communicate its status. Basically, this is the way our browser knows whether the website exists or not (or if the server is down) and whether we may have typed the URL improperly.
We all have probably see the 404 status code indicating the website is down or unavailable or we typed the URL wrong. We probably have never see the status code 200, because that indicates that everything went properly—but our browser does see it.
Here is a summary of the most important HTTP status codes that every browser uses and DirBuster utilizes to find directories and files in websites.
- 100 Continue - Codes in the 100 range indicate that, for some reason, the client request has not been completed and the client should continue.
- 200 Successful - Codes in the 200 range generally mean the request was successful.
- 300 Multiple Choices - Codes in the 300 range can mean many things, but generally they mean that the request was not completed.
- 400 Bad Request - The codes in the 400 range generally signal a bad request. The most common is the 404 (not found) and 403 (forbidden).
Now, let's get started using DirBuster. Once again, we are fortunate enough that it is built into Kali Linux, so it's not necessary to download or install any software.
Fire Up Kali & Open DirBuster
Let's start by opening Kali and then opening DirBuster. We can find DirBuster at Applications -> Kali Linux -> Web Applications -> Web Crawlers -> dirbuster, as seen in the screenshot below.
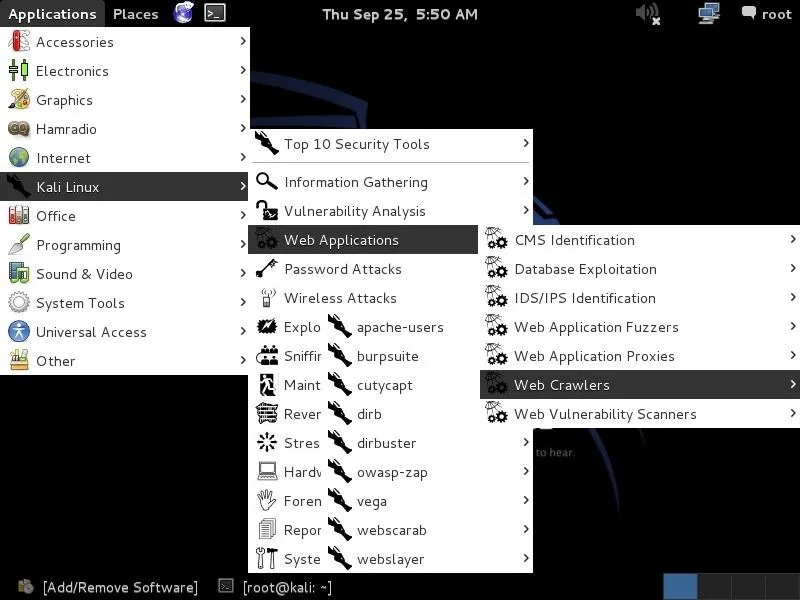
Open DirBuster
When we click on "dirbuster," it opens with a GUI like that below. The first step is it to type in the name of the website we want to scan. Let's go back to our friends at SANS, one of the world's leading IT security training and consulting firms. Simply type in the URL of the site you want to scan and the port number (usually 80 for HTTP and 443 for HTTPS). In this case, we will scan port 80.
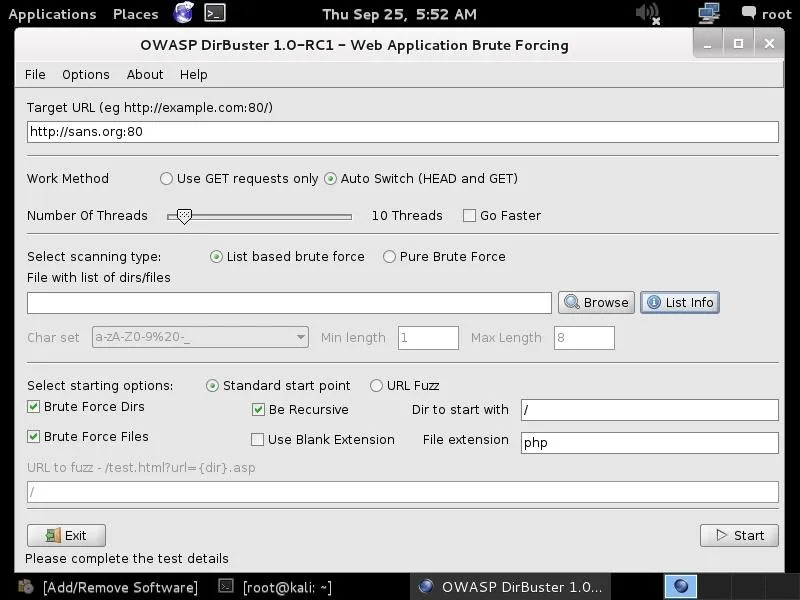
Choose a Wordlist
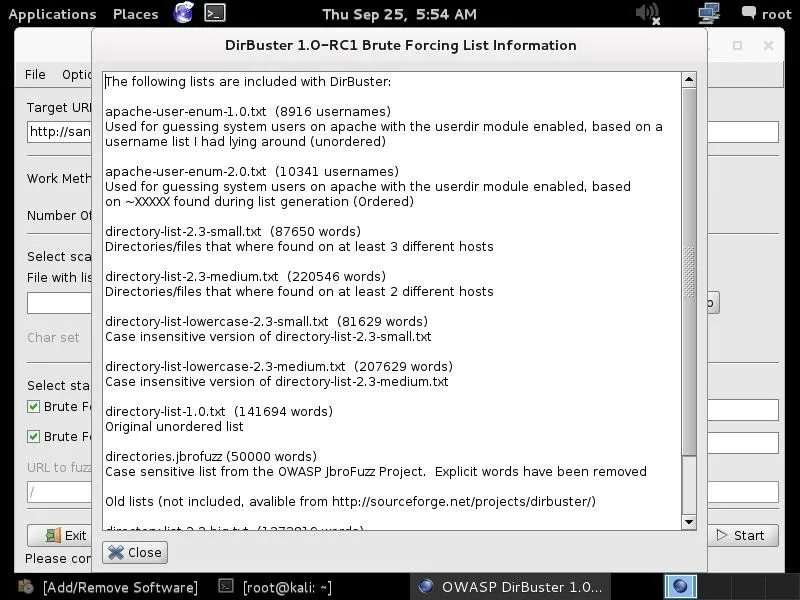
The next step is to choose a wordlist we want to use to find the directories and files. Go to the center of the GUI where it says "files with lists of dir/files" and click on "List Info" in the bottom far right. When you do, it will open a screen like that below listing all the available wordlists with a short description.
Simply choose the list you want to use and enter into the "File with dir/file" field in the GUI. Here, I have chosen to use:
/usr/share/dirbuster/wordlists/directory-list-2.3-medium.txt
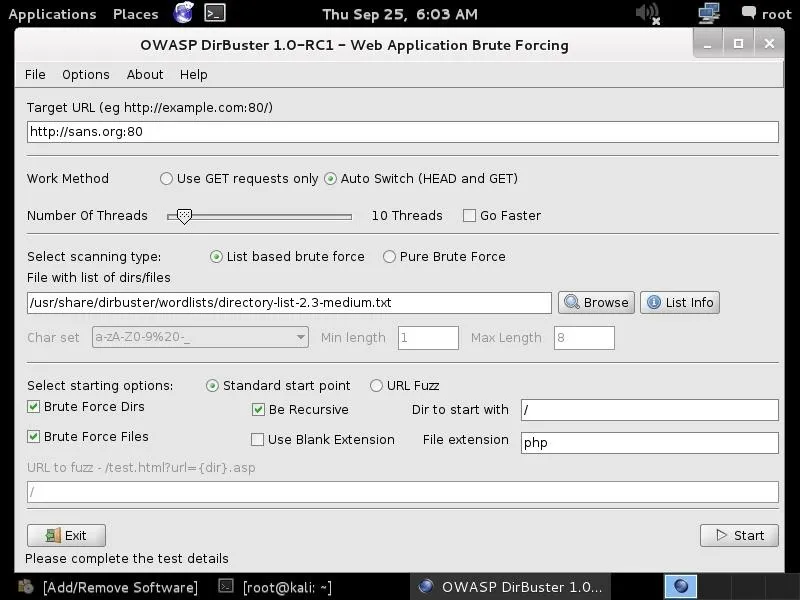
Start!
In the final step, we simply click on the "Start" button. When we do so, DirBuster will start generating GET requests and sending them to our selected URL with a request for each of the files and directories listed in our wordlist.
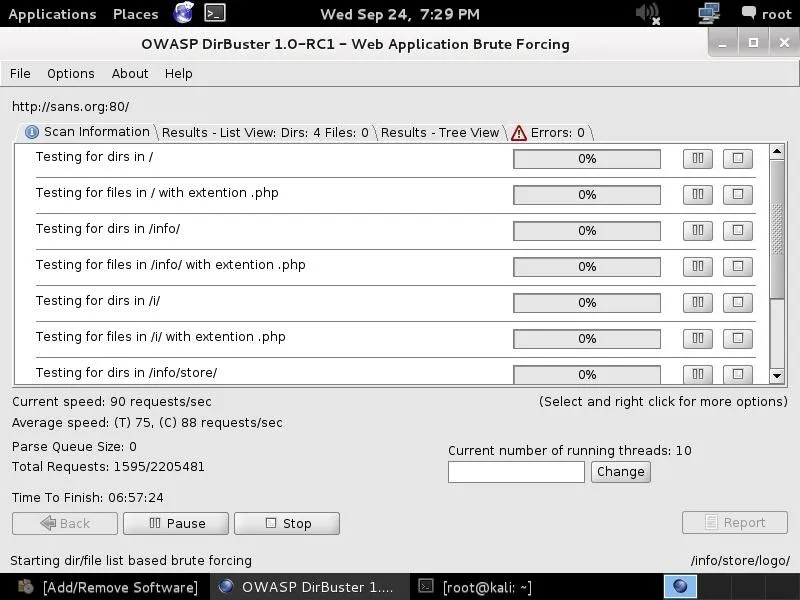
As you can see, after three hours of running, DirBuster is beginning to develop a directory structure of the www.sans.org website from the responses it receives from the requests.
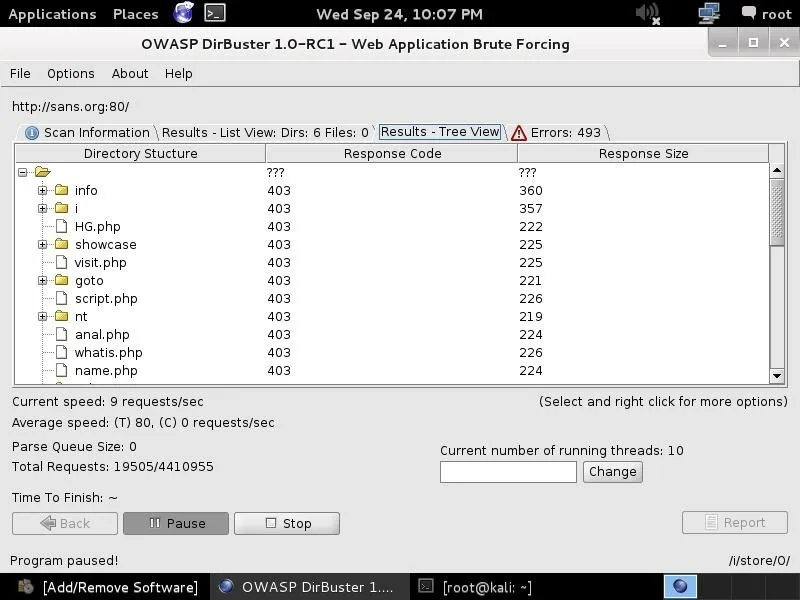
DirBuster is another tool we can use to do reconnaissance on target websites before attacking. The more information we have, the greater our chances of success.
I'll keep showing you more tools and techniques for hacking, so keep coming back, my novice hackers!




















Comments
Be the first, drop a comment!