




While attempting to hack a web app, there may come a point where the attacker may have to escape the default directory in order to access unauthorized files. This is known as a directory traversal attack. Much as the name implies, this attack involved traversing the servers directories.

But in order to move to an unauthorized directory, we need to know where those directories are. Today we'll be building a tool to brute force these directory locations based on HTTP response codes. Before we get into the code, let's review how this attack will work.
There are many HTTP response codes that are used when communicating with a web server. But there are only two that matter to us today, 200 and 404. The 200 (OK) code is used when a valid page or directory is requested. You're most likely already familiar with the 404 error code. It is used when the requested page or directory doesn't exist.
By sending requests for possible directories, we can evaluate the response in order to tell if we can traverse to this newly discovered directory. Now that we know how this works, let's get to the code!
Import Modules and Set the Interpreter Path
First things first, we'll need to set our interpreter path. This marks our file as a python script. After we set our interpreter path, we'll import all our modules. Let's see this bit of code, then we'll brief each module:
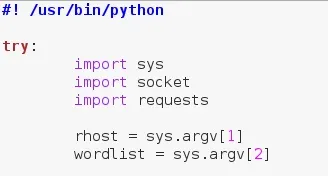
It's also worth noting that we're going to place everything into a single try and except block. This is to catch any interrupts the user gives to ensure that no error messages spill everywhere. Also, we've taken two arguments from the command line, the target and a word list of paths to use in the brute force.
We can also see that we've imported three modules. Let's briefly cover their purposes:
- sys - Used to take command line arguments and exit when needed.
- socket - Used to test for a valid URL.
- requests - Used to make HTTP requests and receive response code.
Now that we have our interpreter path, modules, and input, let's move on to checking the URL the user gives. We can't brute force directories on a web site that doesn't exist!
Evaluate the URL
When we took the input, we set a variable named rhost. Short for remote host, this is the target. But, since we're brute forcing directories here, this needs to be a URL.
First we need to test to see if the given URL exists and is reachable. We can verify this by making a test connection to it using sockets. We'll simply make a socket, and use the connect_ex() method to test the URL. This method returns a zero if the connection was successful, and an error otherwise. Let's take a look at this code:
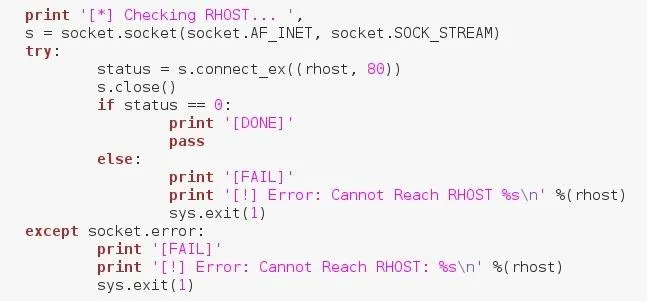
We can see here that we've told the user that we're checking the URL they gave us, and we've made a socket. We then used the previously mentioned connect_ex() and assigned it's output to the status variable. If the result is zero, we move on, but if there's an error or the result isn't zero, we print that we can't reach the RHOST and exit the script.
Now that we've tested the URL, let's move on to reading the word list.
Read the Specified Word List
Since the user gave us the path to a word list, we need to read and parse it in order to use the paths within it. We'll by placing all of this inside a try/except block just in case any errors in the I/O process occur. Let's take a deeper look at this code now:
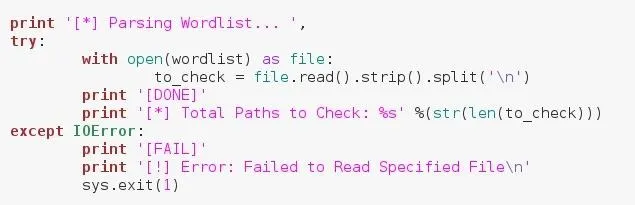
We've opened the word list under an alias with the temporary name file. We then make a new variable with the name to_check. This will be a list of paths to check.
Then we call .read() on our file to get the contents, we then call .strip() to get rid of the extra newline at the end of the file (this extra newline is present in all files), then we call .split() with the newline character as our split marker. This will result in a list of all paths in the file stored under our to_check variable.
Once we've read the file, we tell the user and print the total number of paths to check. We get this number by converting the length of the to_check list to a string.
Now that we've read and parsed our word list, we can make the function we'll use to make requests and receive the response codes.
Make the Path Checking Function
To make this a bit easier, we'll just be making a function to check a single path, then we'll loop through our list and feed each element to the function. We'll start by making the request and storing the response code in a variable. Then we'll quickly evaluate the response from within the function. Let's take a look at our function:

We've named our function checkpath and it takes one argument under the name path. We then call requests.get() to make the request. We have to add the "https://" protocol to the URL in order for the requests module to function properly, we also added a slash to the end of the URL just in case the user did not.
We store the status code from this request into the variable result. We also placed this within a try/except just in case an unexpected error occurs. Once we have our response, we test for the 200 status code and, if it is, we print that a valid path has been found, followed by the path.
Now that we have our function, we just need to loop through our list and use it.
Iterate Over the List of Paths
Now that we have our function, we can use it. We'll first print that the scan is starting, then we'll loop through the to_check list, calling our function for every element. Let's take a look at this code:
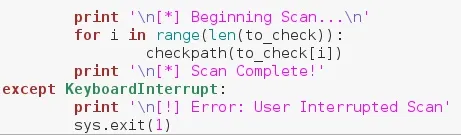
Here we have a standard for loop, calling our function for each element in the list. Once we're done, we print a newline, followed by confirmation that the scan is complete. That's the end of our code, so let's test it out.
Test It Out
Now that we have this tool (Pastebin or Null Byte Suite) we need to test it. We'll be testing on a very handy site, webscantest. First, let's make a word list. This file will contain a bunch of possible paths to test:
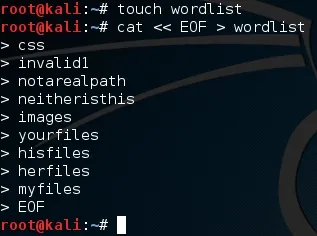
There we go, we have our word list, now let's fire up our tool and do some brute forcing. We'll need to give the URL then the path to the word list in the command line. Let's launch our tool now:
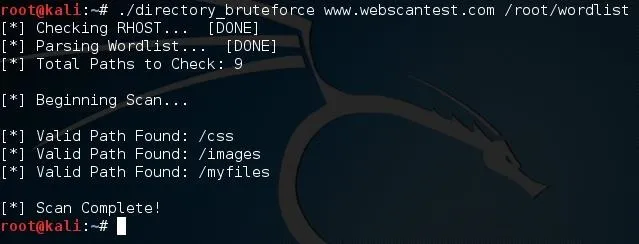
There we have it. Three out of our nine paths returned as valid! Let's open up one of them just to make sure. We'll try out the /images path:
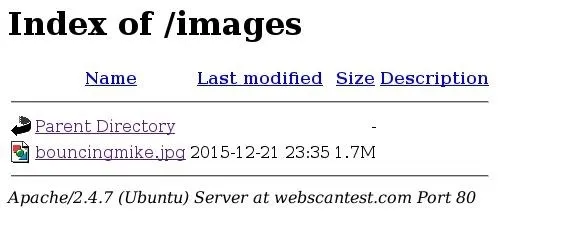
This is in fact a valid directory, but it only contains a picture of a guy in a bouncy castle. But, this proves that our tool works! We covered some interesting concepts here, so let's wrap this up, shall we?
Wrapping It Up
Today we covered the concepts of directory traversal, and we built a tool to brute force these attack-able directories! If you have any questions or concerns, please leave them below and I'm sure they'll be addressed.
Thank you for reading!
-Defalt




















Comments
Be the first, drop a comment!