




Welcome back, my aspiring hackers!
In recent tutorials, I have made reference to the name and location of the Linux devices in the file system, such as sda (first SATA or SCSI drive). Specifically, I have mentioned the way that Linux designates hard drives when making an image of a hard drive for forensic purposes.
Fundamental to understanding how to use and administer hard drives and other devices in Linux is an understanding of how Linux specifies these devices in its file system.
Very often, if we are using are hard drive in a hack or in forensics, we will need to specifically address its device file name. These device file names allow the device (e.g. hard drive) to interact with system software and kernel through system calls. These files are NOT device drivers, but rather rendezvous points that are used to communicate to the drivers. Linux maintains a device file for every device in the system in the /dev directory.
In this tutorial, we will examine how Linux names and interacts with the file system through the /dev directory and its files.
The /Dev Directory
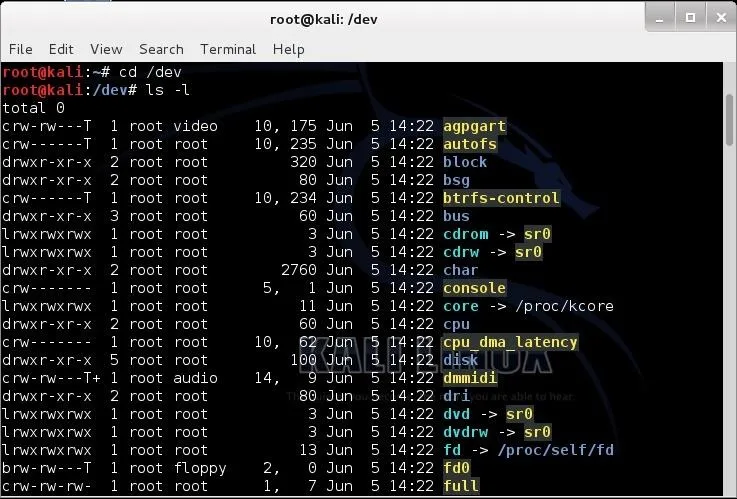
The /dev directory contains all the files that represent physical peripheral devices present on the system such as disk drives, terminals, and printers. The /dev directory is directly below the / directory. If we navigate there, we will see an entry for all of our devices.
kali > cd /dev
kali > ls -l
Block v. Character Devices
Linux makes a distinction between block and character devices. Character devices are those that stream data into and out of the machine unbuffered and directly. These would include your keyboard, mouse, tape, and monitor. Because the data is unbuffered, it tends to be a slow process.
On the other hand, block devices are those that stream data into and out of the machine in buffered blocks. These include such devices as hard drives, CDs, DVDs, floppies, flash drives, etc. This data transfer tends to be much faster.
Notice in the long listing of the /dev directory that some files begin with a "c" and some with a "b". Character devices begin a with "c " and block devices begin with a "b".
You will notice in the third line of the /dev directory listing that there is directory named "block". Let's navigate there and do a long list.
kali > cd /block
kali > ls -l
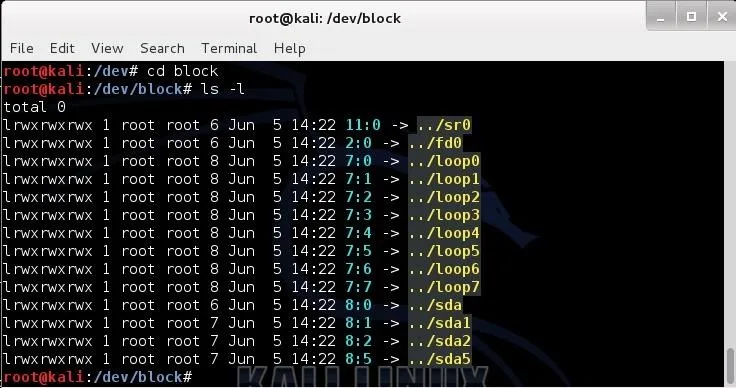
Here we see a listing of all the block devices. In the first line we see sr0; that would be the first CD-ROM (Linux tends to begin counting at 0, not 1). Near the bottom, we see sda, sda1, sda2, sda5 (yours may be different), where sda1 represents the first primary partition on the SATA drive, and sda2 represents the second primary partition on the SAME drive.
Naming Conventions of Devices in Linux
Originally, hard drives were two types, IDE or SCSI. IDE (or later, E-IDE) was designed as a low cost alternative for low cost PCs. They were relatively slow and only allowed four devices per machine. In addition, they had to be configured in a master and slave configuration. Each master and slave combination had one cable and controller.
A faster, but more expensive alternative was the SCSI (Small Computer System Interface) drive. SCSI drives were (are) faster and pricier. Besides their speed advantage, they did not need a master/slave configuration, but rather were configured with a controller and a series of devices up to 15.
Linux would designate IDE hard drives with an hd and SCSI hard drives with an sd. In recent years, with the development and proliferation of SATA drives, we see that Linux designates these drives with sd, just like SCSI drives.
The first IDE drive was designated with an hda, the second hdb, the third hdc, and so on. The same happens with SCSI and now SATA drives; the first is designated with sda, the second sdb, the third sdc, and so on.
Some other devices files include:
- /dev/usb - USB devices
- /dev/lp - parallel port printer
- /dev/tty - local terminal
- /dev/fd - floppy drive (does anyone still use floppies?)
Logical vs. Physical Partitions of Hard Drives
Linux is able to recognize four (4) primary hard drive partitions per operating system. This doesn't limit us to four hard drives or four partitions as we can also use logical or extended partitions. We can have up to 15 logical or extended partitions per disk and each of these partitions acts as its own hard drive and operates just as fast as a primary partition.
The first primary partition in Linux with a SATA drive would be sda1, the second sda2, the third sda3, and the fourth sda4. Beyond these primary partitions, we can still partition the drive, but they are now logical partitions. The first logical partition would be sda5 with a SATA drive. This can then be followed by 14 more logical drives, if needed, with the last logical drive on the first SATA drive being sda19 (4 primary and 15 logical partitions).
In Linux, we generally have a separate partition for swap space. Swap space is that area of the hard drive that is used as virtual memory. This means that when we run out of memory (RAM) for a particular process or application, the operating system will then use this hard drive space as if it were RAM, but obviously, much slower (about 1,000x slower).
Special Devices
Linux has a number of special device files. This is a list of a few of the most important special device files.
/dev/null
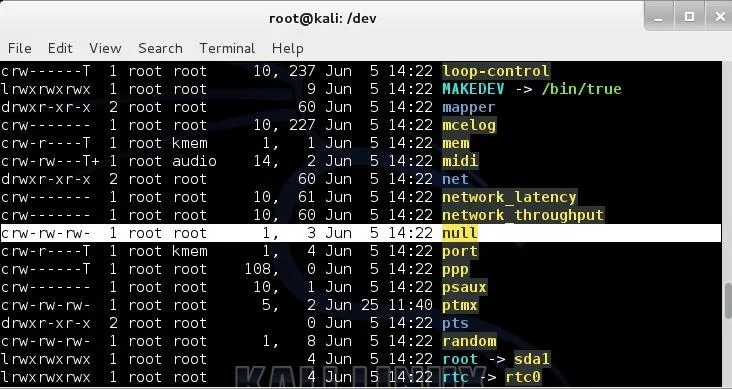
This device is a data sink or "bit bucket". It makes data disappear. If you redirect output to this device it will disappear. If you read from /dev/null, you will get a null string. If I wanted to wipe a drive clean, deleting all the data, I could use:
dd if=/dev/null of=/dev/sda
/dev/zero
This device can be used as an input file to provide as many null bytes (0x00) as necessary. It is often used to initialize a file or hard drive.
/dev/ full
This device is a special file that always returns the "device full" error. Usually, it is used to test how a program reacts to a "disk full" error. It is also able to provide an infinite number of null byte characters to any process for testing.
/dev/random
This device can be used as an input to fill a file or partition with random, or more precisely, pseudo-random data. I might use this to overwrite a file or partition to make it much harder to recover deleted files by a forensic investigator.
It's almost impossible to remove evidence of a file from recovery by a skilled forensic investigator with unlimited time and money. Since few forensic investigators have the skill or the time or the money, this technique will inhibit most forensic investigations.
To do this, we can use the dd command. For instance:
dd if=/dev/random of=evidencefile bs=1 count=1024
I hope this sheds some light on this relatively foreign concept—native to Linux—that Windows users often struggle with. For more guides on Linux, check out all of my past Linux Basics guides, and keep a lookout for more to come.




















Comments
Be the first, drop a comment!