




When researching a person using open source intelligence, the goal is to find clues that tie information about a target into a bigger picture. Screen names are perfect for this because they are unique and link data together, as people often reuse them in accounts across the internet. With Sherlock, we can instantly hunt down social media accounts created with a unique screen name on many online platforms simultaneously.
From a single clue like an email address or screen name, Sherlock can grow what we know about a target piece by piece as we learn about their activity on the internet. Even if a person is careful, their online contacts may not be, and it's easy to slip up and leave default privacy setting enabled on apps like Venmo. A single screen name can reveal many user accounts created by the same person, potentially introducing photos, accounts of family members, and other avenues for collecting further information.
What Sherlock Can Find
Social media accounts are rich sources of clues. One social media account may contain links to others which use different screen names, giving you another round of searching to include the newly discovered leads. Images from profile photos are easy to put into a reverse image search, allowing you to find other profiles using the same image whenever the target has a preferred profile photo.
Even the description text in a profile may often be copied and pasted between profiles, allowing you to search for profiles created with identical profile text or descriptions. For our example, I'll be taking the suggestion of a fellow Null Byte writer to target the social media accounts of Neil Breen, director of many very intense movies such as the classic hacker film Fateful Findings.
What You'll Need
Python 3.6 or higher is required, but aside from that, you'll just need pip3 to install Sherlock on your computer. I had it running on macOS and Ubuntu just fine, so it seems to be cross-platform. If you want to learn more about the project, you can check out its simple GitHub page.
- Don't Miss: How to Use SpiderFoot for OSINT Gathering
Install Python & Sherlock
To get started, we can follow the instructions included in the GitHub repository. In a new terminal window, run the following commands to install Sherlock and all dependencies needed.
~$ git clone https://github.com/sherlock-project/sherlock.git
~$ cd sherlock
~/sherlock$ pip3 install -r requirements.txtIf something fails, make sure you have python3 and python3-pip installed, as they're required for Sherlock to install. Once it's finished installing, you can run python3 sherlock.py -h from inside the /sherlock folder to see the help menu.
~/sherlock$ python3 sherlock.py -h
usage: sherlock.py [-h] [--version] [--verbose] [--rank]
[--folderoutput FOLDEROUTPUT] [--output OUTPUT] [--tor]
[--unique-tor] [--csv] [--site SITE_NAME]
[--proxy PROXY_URL] [--json JSON_FILE]
[--proxy_list PROXY_LIST] [--check_proxies CHECK_PROXY]
[--print-found]
USERNAMES [USERNAMES ...]
Sherlock: Find Usernames Across Social Networks (Version 0.5.8)
positional arguments:
USERNAMES One or more usernames to check with social networks.
optional arguments:
-h, --help show this help message and exit
--version Display version information and dependencies.
--verbose, -v, -d, --debug
Display extra debugging information and metrics.
--rank, -r Present websites ordered by their Alexa.com global
rank in popularity.
--folderoutput FOLDEROUTPUT, -fo FOLDEROUTPUT
If using multiple usernames, the output of the results
will be saved at this folder.
--output OUTPUT, -o OUTPUT
If using single username, the output of the result
will be saved at this file.
--tor, -t Make requests over TOR; increases runtime; requires
TOR to be installed and in system path.
--unique-tor, -u Make requests over TOR with new TOR circuit after each
request; increases runtime; requires TOR to be
installed and in system path.
--csv Create Comma-Separated Values (CSV) File.
--site SITE_NAME Limit analysis to just the listed sites. Add multiple
options to specify more than one site.
--proxy PROXY_URL, -p PROXY_URL
Make requests over a proxy. e.g.
socks5://127.0.0.1:1080
--json JSON_FILE, -j JSON_FILE
Load data from a JSON file or an online, valid, JSON
file.
--proxy_list PROXY_LIST, -pl PROXY_LIST
Make requests over a proxy randomly chosen from a list
generated from a .csv file.
--check_proxies CHECK_PROXY, -cp CHECK_PROXY
To be used with the '--proxy_list' parameter. The
script will check if the proxies supplied in the .csv
file are working and anonymous.Put 0 for no limit on
successfully checked proxies, or another number to
institute a limit.
--print-found Do not output sites where the username was not found.As you can see, there are lots of options here, including options for using Tor. While we won't be using them today, these features can come in handy when we don't want anyone to know who is making these requests directly.
Identify a Screen Name
Now that we can see how the script runs, it's time to run a search. We'll load up our target, Neil Breen, with a screen name found by running a Google search for "Neil Breen" and "Twitter."
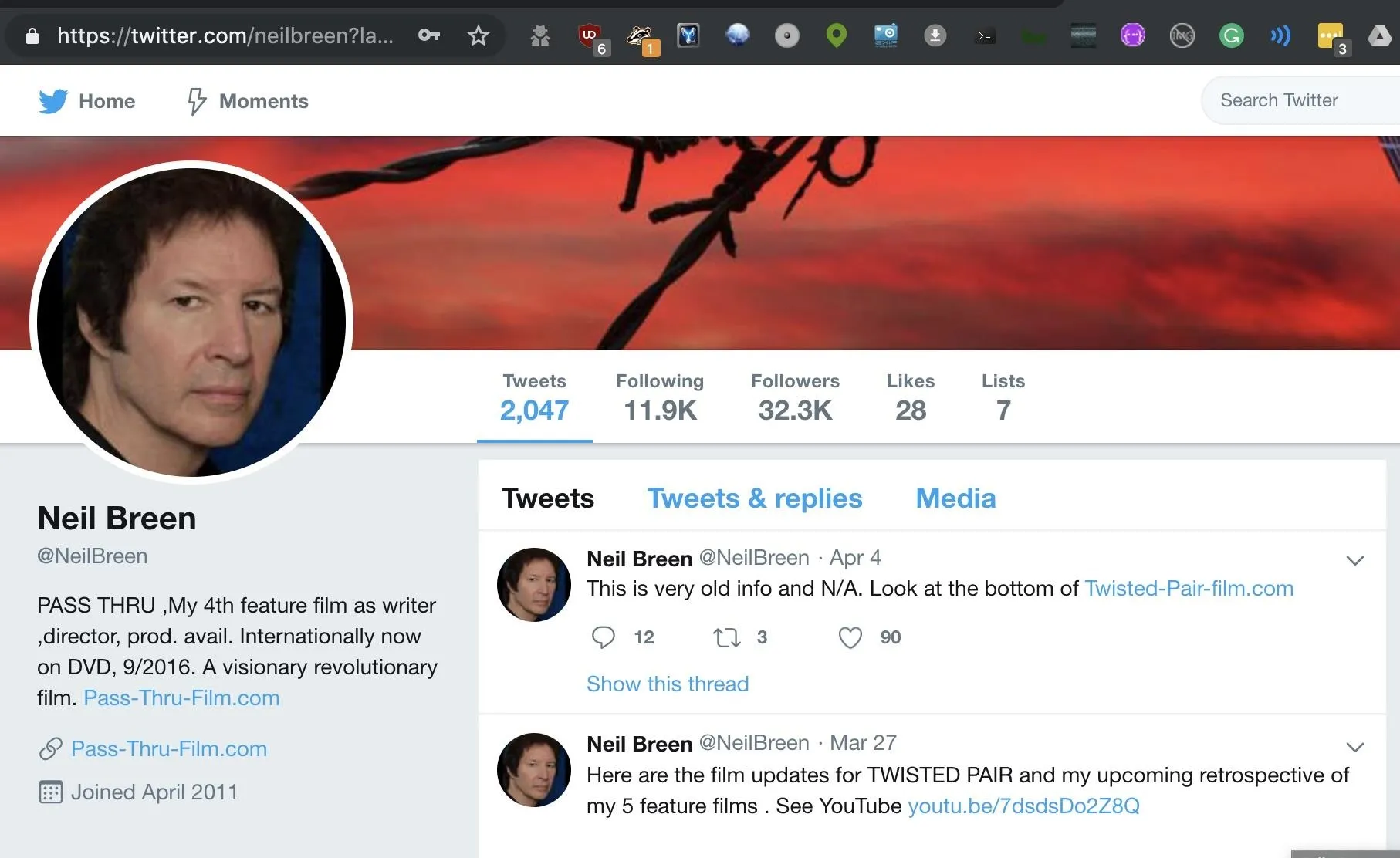
That's our guy. The screen name we'll be searching is neilbreen. We'll format that as the following command, which will search for accounts across the internet with the username "neilbreen" and print only the results that it finds. It will significantly reduce the output, as the majority of queries will usually come back negative. The final argument, -r, will organize the list of found accounts by which websites are most popular.
~/sherlock$ python3 sherlock.py neilbreen -r --print-foundScan for Accounts
Upon running this command, we will see a lot of output without the --print found flag regardless of the results. In our neilbreen example, we are taken on a virtual tour of Neil Breen's life across the internet.
~/sherlock$ python3 sherlock.py neilbreen -r --print-found
."""-.
/ \
____ _ _ _ | _..--'-.
/ ___|| |__ ___ _ __| | ___ ___| |__ >.`__.-""\;"`
\___ \| '_ \ / _ \ '__| |/ _ \ / __| |/ / / /( ^\
___) | | | | __/ | | | (_) | (__| < '-`) =|-.
|____/|_| |_|\___|_| |_|\___/ \___|_|\_\ /`--.'--' \ .-.
.'`-._ `.\ | J /
/ `--.| \__/
[*] Checking username neilbreen on:
[+] Google Plus: https://plus.google.com/+neilbreen
[+] Facebook: https://www.facebook.com/neilbreen
[+] Twitter: https://www.twitter.com/neilbreen
[+] VK: https://vk.com/neilbreen
[+] Reddit: https://www.reddit.com/user/neilbreen
[+] Twitch: https://m.twitch.tv/neilbreen
[+] Ebay: https://www.ebay.com/usr/neilbreen
[-] Error Connecting: GitHub
[-] GitHub: Error!
[+] Imgur: https://imgur.com/user/neilbreen
[+] Pinterest: https://www.pinterest.com/neilbreen/
[-] Error Connecting: Roblox
[-] Roblox: Error!
[+] Spotify: https://open.spotify.com/user/neilbreen
[+] Steam: https://steamcommunity.com/id/neilbreen
[+] SteamGroup: https://steamcommunity.com/groups/neilbreen
[+] SlideShare: https://slideshare.net/neilbreen
[+] Medium: https://medium.com/@neilbreen
[-] Error Connecting: Scribd
[-] Scribd: Error!
[+] Academia.edu: https://independent.academia.edu/neilbreen
[+] 9GAG: https://9gag.com/u/neilbreen
[-] Error Connecting: GoodReads
[-] GoodReads: Error!
[+] Wattpad: https://www.wattpad.com/user/neilbreen
[+] Bandcamp: https://www.bandcamp.com/neilbreen
[+] Giphy: https://giphy.com/neilbreen
[+] last.fm: https://last.fm/user/neilbreen
[+] AskFM: https://ask.fm/neilbreen
[+] Disqus: https://disqus.com/neilbreen
[+] Tinder: https://www.gotinder.com/@neilbreen
[-] Error Connecting: Kongregate
[-] Kongregate: Error!
[+] Letterboxd: https://letterboxd.com/neilbreen
[+] 500px: https://500px.com/neilbreen
[+] Newgrounds: https://neilbreen.newgrounds.com
[-] Error Connecting: Trip
[-] Trip: Error!
[+] Venmo: https://venmo.com/neilbreen
[+] NameMC (Minecraft.net skins): https://namemc.com/profile/neilbreen
[+] Repl.it: https://repl.it/@neilbreen
[-] Error Connecting: StreamMe
[-] StreamMe: Error!
[+] CashMe: https://cash.me/neilbreen
[+] Kik: https://ws2.kik.com/user/neilbreenAside from this output, we've also got a handy text file that's been created to store the results. Now that we have some links, let's get creepy and see what we can find from the results.
Check Target List for More Clues
To review our target list, type ls to locate the text file that was created. It should be, in our example, neilbreen.txt.
~/sherlock$ ls
CODE_OF_CONDUCT.md install_packages.sh __pycache__ screenshot tests
CONTRIBUTING.md LICENSE README.md sherlock.py
data.json load_proxies.py removed_sites.md site_list.py
Dockerfile neilbreen.txt requirements.txt sites.mdWe can read the contents by typing the following cat command, which gives us plenty of URL targets to pick from.
~/sherlock$ cat neilbreen.txt
https://plus.google.com/+neilbreen
https://www.facebook.com/neilbreen
https://www.twitter.com/neilbreen
https://vk.com/neilbreen
https://www.reddit.com/user/neilbreen
https://m.twitch.tv/neilbreen
https://www.ebay.com/usr/neilbreen
https://imgur.com/user/neilbreen
https://www.pinterest.com/neilbreen/
https://open.spotify.com/user/neilbreen
https://steamcommunity.com/id/neilbreen
https://steamcommunity.com/groups/neilbreen
https://slideshare.net/neilbreen
https://medium.com/@neilbreen
https://independent.academia.edu/neilbreen
https://9gag.com/u/neilbreen
https://www.wattpad.com/user/neilbreen
https://www.bandcamp.com/neilbreen
https://giphy.com/neilbreen
https://last.fm/user/neilbreen
https://ask.fm/neilbreen
https://disqus.com/neilbreen
https://www.gotinder.com/@neilbreen
https://letterboxd.com/neilbreen
https://500px.com/neilbreen
https://neilbreen.newgrounds.com
https://venmo.com/neilbreen
https://namemc.com/profile/neilbreen
https://repl.it/@neilbreen
https://cash.me/neilbreen
https://ws2.kik.com/user/neilbreenA few of these we can rule out, like Google Plus, which has now shut down. Others can be much more useful, depending on the type of result we get. Due to Neil Breen's international superstar status, there are many fan accounts sprinkled in here. We'll need to use some common-sense techniques to rule them out while trying to locate more information about this living legend.
First, we see that there is a Venmo and Cash.me account listed. While these don't pan out here, many people leave their Venmo payments public, allowing you to see who they are paying and when. In this example, it appears this account was set up by a fan to accept donations on behalf of Neil Breen. A dead end.
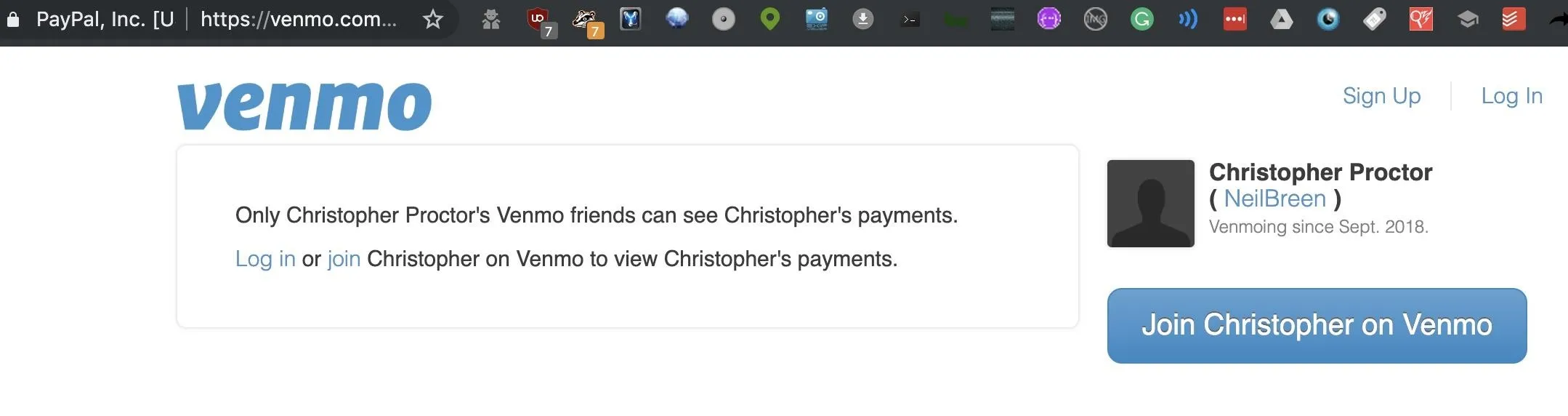
Next, we move down the list, which is organized by a ranking of which sites are most popular. Here, we see an account that's more likely to be a personal account.
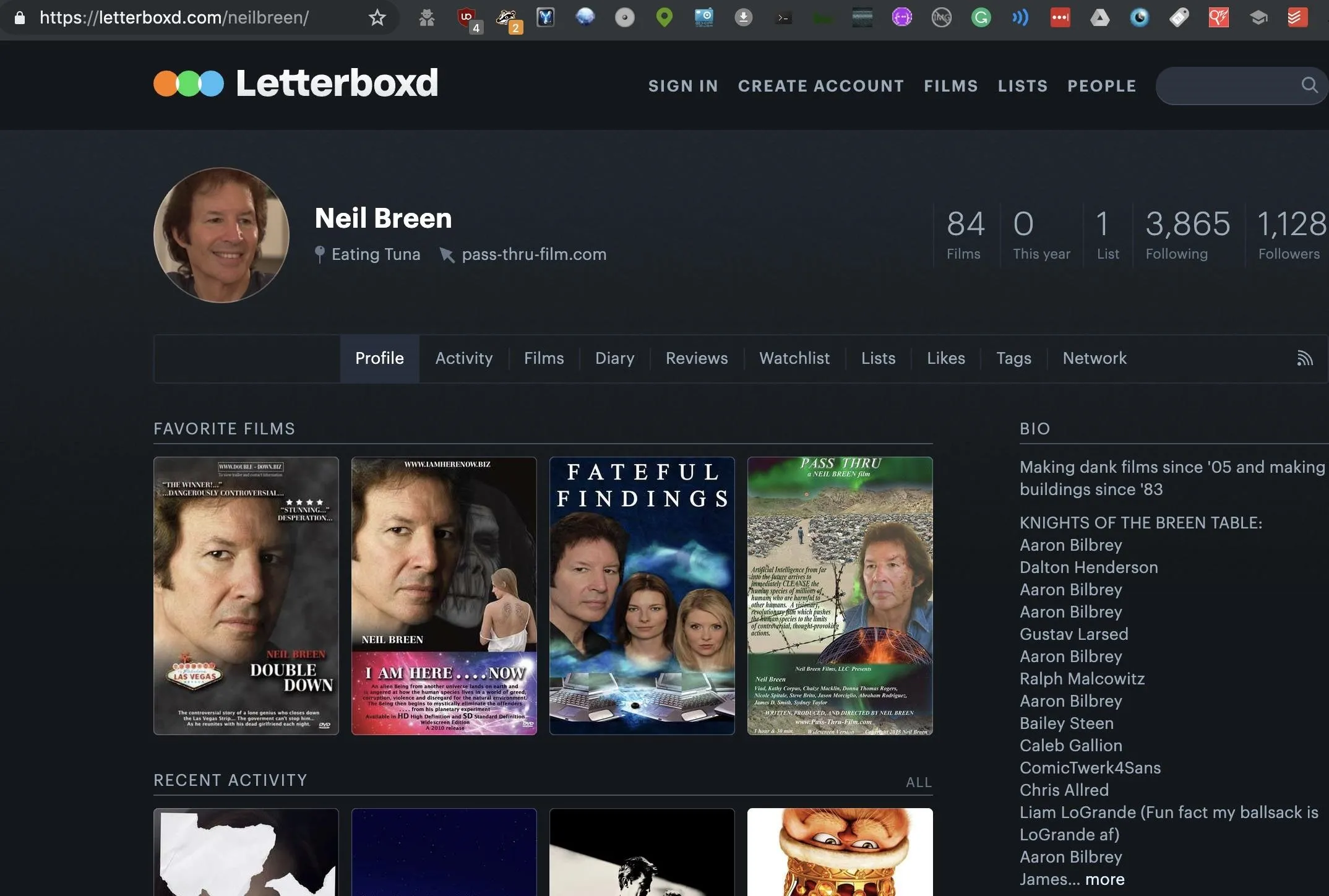
The link above also takes us to a very insecure website for a Neil Breen movie called "Pass-Thru" which could, and probably does, have many vulnerabilities.
A reverse image search of Neil's Letterboxd and Twitter profile images also locate another screen name the target uses: neil-breen. It leads back to an active Quora account where the target advises random strangers.
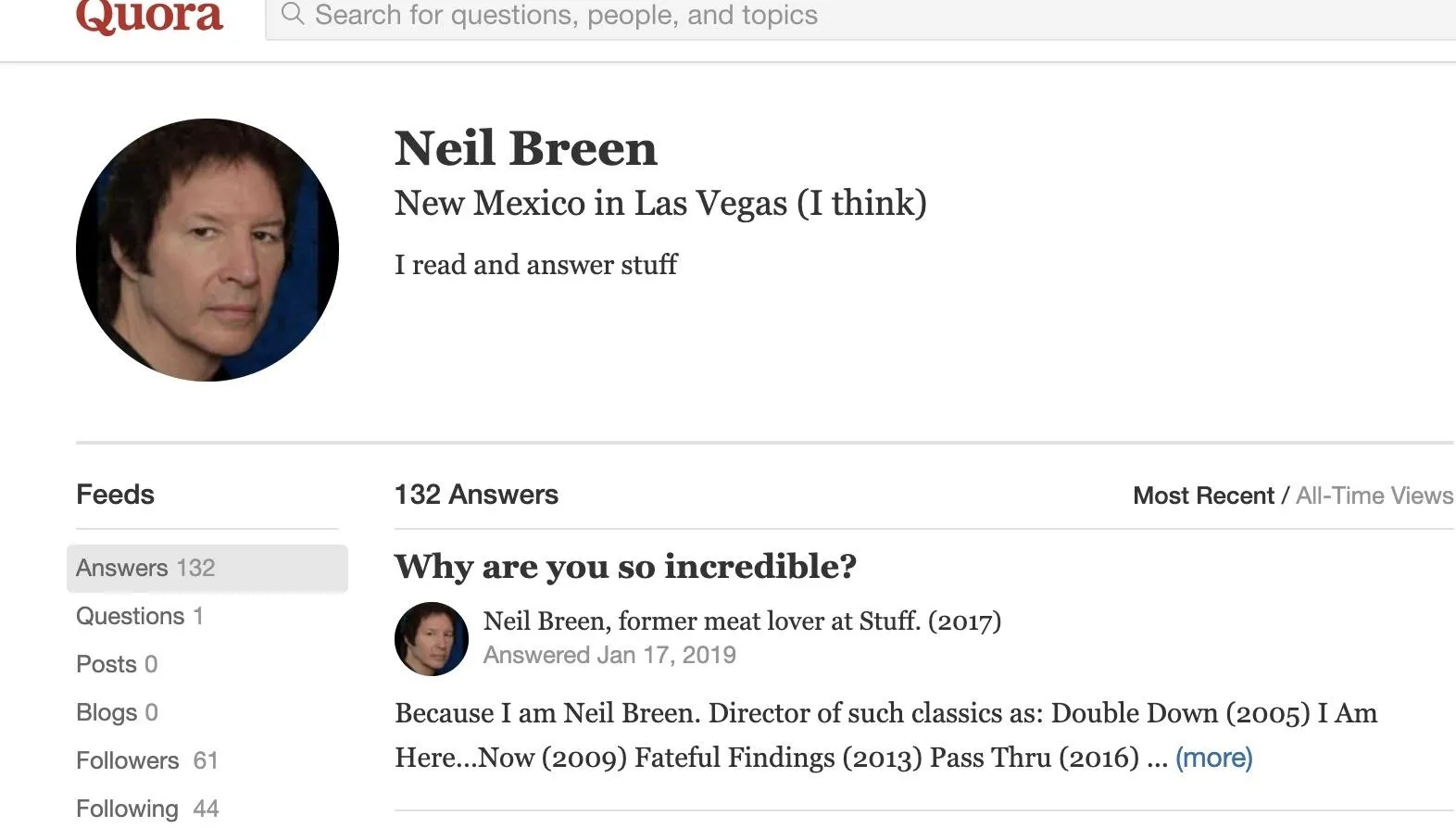
Already, we've taken one screen name, and through the profile image, found another screen name that we didn't initially know about.
Another common source of information are websites people use to share information. Things like SlideShare or Prezi allow users to share presentations that are visible to the public.
If the target has made any presentations for work or personal reasons, we can see them here. In our case, we didn't find much. But a search through the Reddit account we found shows that the account dates back to before Neil Breen got huge.
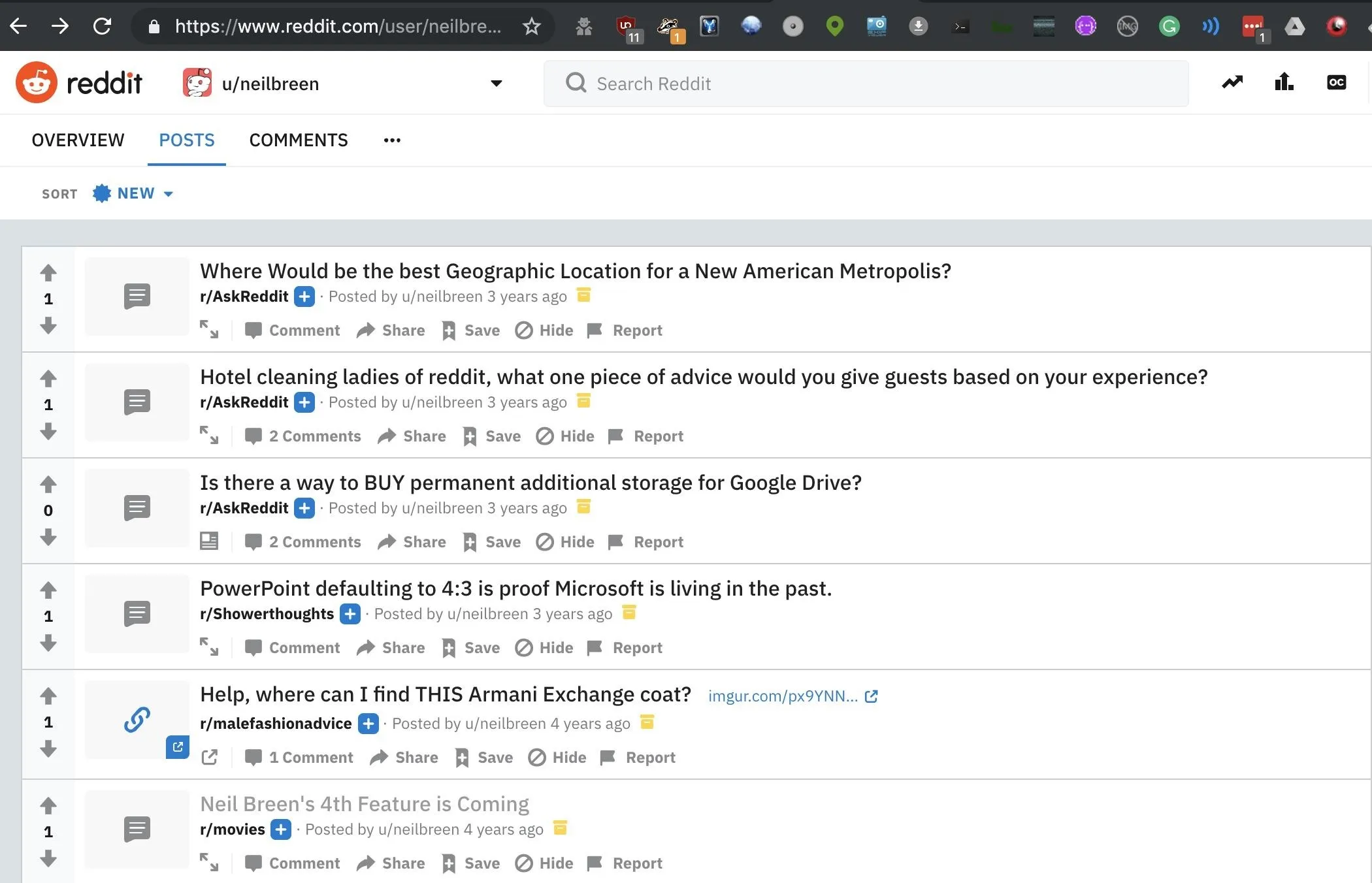
The first post is promoting his movie, so that plus the age of the account means it's likely this one is legit. We can see that Neil likes Armani exchange, struggles with technology, and is trying to get ideas for where to set his next movie.
Finally, our crown gem is an active eBay account, which allows us to see many things Neil buys and read reviews from sellers he's had transactions with.
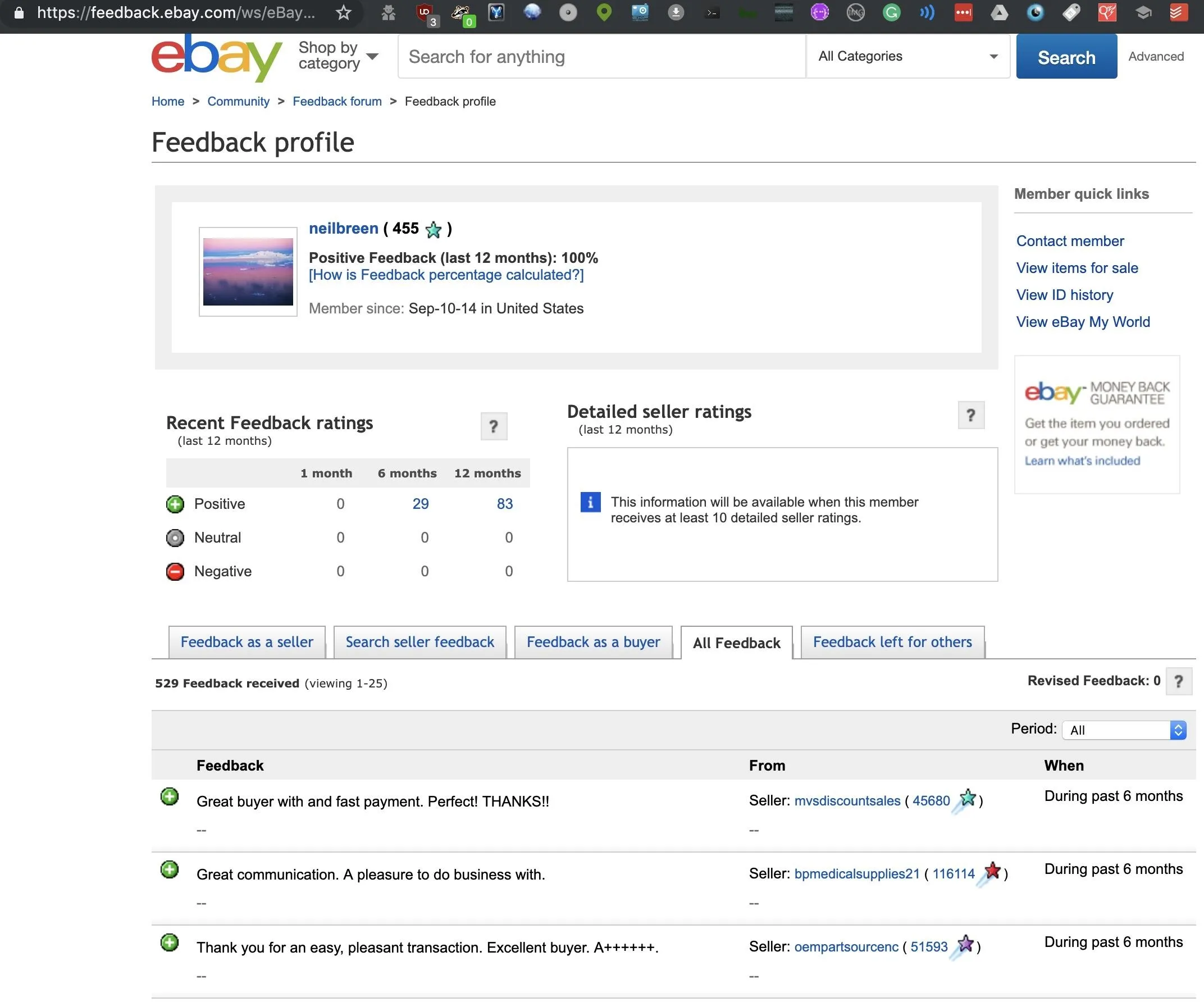
The info here lets us dig into hobbies, professional projects, and other details leaked through purchases verified by eBay and listed publicly under that screen name.
Sherlock Can Connect the Dots Across User Accounts
As we found during our sample investigation, Sherlock provides a lot of clues to locate useful details about a target. From Venmo financial transactions to alternative screen names found through searching for favorite profile photos, Sherlock can bring in a shocking amount of personal details. The next step in our investigation would be to rerun Sherlock with the new screen names we've located during our first run, but we'll leave Neil alone for today.
I hope you enjoyed this guide to using Sherlock to find social media accounts! If you have any questions about this tutorial on OSINT tools, leave a comment below, and feel free to reach me on Twitter @KodyKinzie.
Cover image and screenshots by Kody/Null Byte




















Comments
Be the first, drop a comment!