




Directory traversal, or path traversal, is an HTTP attack which allows attackers to access restricted directories by using the ../ characters to backtrack into files or directories outside the root folder. If a web app is vulnerable to this, an attacker can potentially access restricted files that contain info about all registered users on the system, their permissions, and encrypted passwords.
Depending on the user permissions web applications grant users, such as read and write, an attacker can leverage a directory path traversal to not only read sensitive files but also replace system files with their own.
As an example, for a web app that lets users download files, we can see if it's vulnerable to path traversal using the dot-dot-slash (../), which is the GNU-Linux/Unix way to escape from the current directory back out to the parent directory. We're navigating away from the app's root directory, typically named /app, back into directories closer to the system files, such as /etc/passwd.
If you are browsing a web application, and the URL reads:
http://shopping-site.com/get-files.php?file=clothingYou could check for a path traversal vulnerability by using ../ to try and escape into a system critical directory:
http://shopping-site.com/get-files?file=../../../../etc/passwdWhile the attack seems simple, it still affects apps and devices to this day. Recently, the security research team at ForeScout, a cybersecurity firm, looked at devices used in BAS networks, which are used to control energy-consuming equipment such as HVAC and lighting controls in buildings. A path traversal vulnerability was among one of the many vulnerabilities they found in the devices.
In this tutorial, we'll be snowballing a path traversal vulnerability on the vulnerable web app Google Gruyere into a code execution vulnerability. The tool we'll use is Burp Suite Community Edition. Burp is an interception proxy, which acts as a man-in-the-middle by capturing each request to and from the target web app so that the pentester can edit, read, and replay individual HTTP requests to search for vulnerabilities and injection points.
Visit Google Gruyere in Your Browser
Before we get started configuring the proxy settings, setting up Burp Suite, and starting up Gruyere, let's first open your web browser of choice to Gruyere's start page. Don't click on anything yet, we'll be agreeing and starting in a future step.
Configure Your Browser for Burp Suite
If you do not have Burp Suite on your computer, you can download and install it on macOS, Linux, and Windows. On Kali Linux, the Community Edition is already installed. Afterward, you'll need to download Burp's CA Certificate, then configure your browser to route traffic to Burp's Proxy. PortSwigger, the company behind Burp Suite, has an excellent guide on setting up the CA Certificate you can follow.
To configure your browser to route traffic so Burp can intercept HTTP and HTTPS requests from a web app, you must set a manual proxy configuration in your browser. The settings can usually be found in "Proxy" or "Network Proxy." Set the HTTP Proxy to be 127.0.0.1 on port 8080, which are the default values Burp uses when it launches.
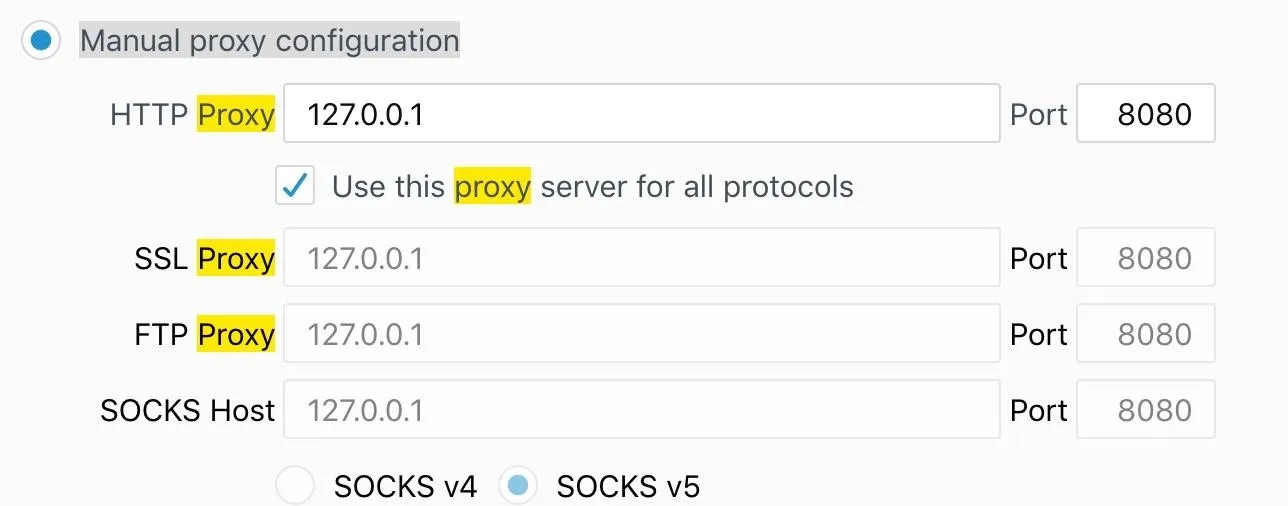
This is how everything should look in Firefox.
Enable Burp to Capture Requests from the Web App
Leave your browser open to the web app you're testing, in this case, the Google Gruyere start page, and launch Burp Suite. Create a temporary project (this will always be the case since all other options are reserved for Burp Suite Pro), then select "use Burp Defaults" which will continue to run Burp with its default proxy settings of 127.0.0.1:8080.
Agree & Start Your Gruyere Session
Now it's time to go back to the Gruyere's start page we opened in Step 1 to agree to the conditions. Click on "Agree & Start." Nothing will happen. By default, when Burp starts, "Intercept" is turned on in the "Proxy" tab. This means your web app will "hang" in the browser as if it's loading because it's waiting for Burp to either forward, drop, or take action on the request.
Begin Mapping the Web App Using Burp's Spider Tool
We'll be using Burp's Spider to map out the web app's content. When we are navigating the web app — following links, submitting forms, and creating an account — the Spider will save all the content of the web app and the navigational paths inside Burp to create a site map for the web app.
The browser tab should still be hanging, waiting for your action in Burp. Check the "Proxy" tab, and you'll notice the GET request to the home page of Gruyere has been "captured." Right-click on the GET request, and click "Send to Spider."
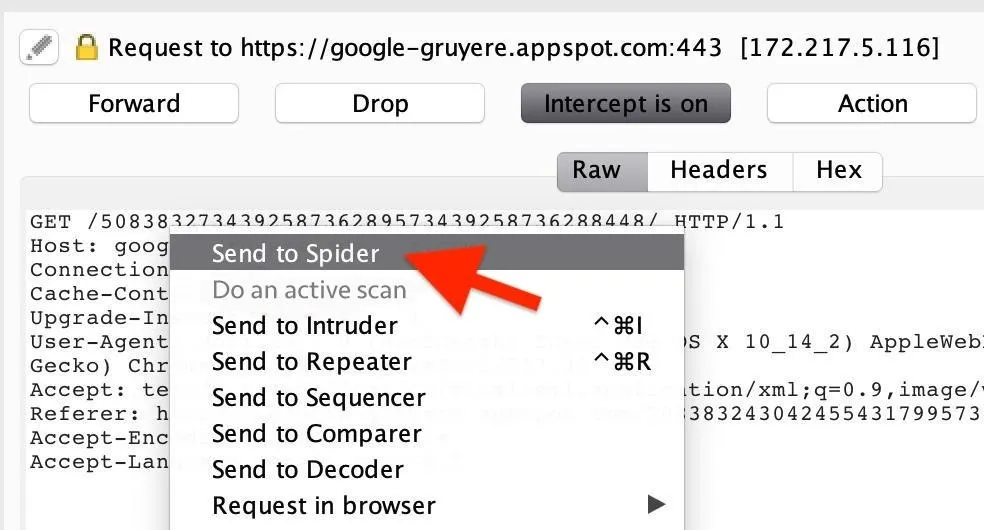
Next, you will be prompted on whether or not you want to add the item to the spidering scope. Select "Yes" to add the web app's host to the target scope so that Burp knows which app's link to begin parsing for content.

Then, select "No" when prompted with the Proxy history logging question. This ensures you have a broad scope, which makes it easier to find more targets. Sending out-of-scope items can lead to discovering portals to other portals where part of the web app is registered, such as a marketing portal, admin portal, and so on.
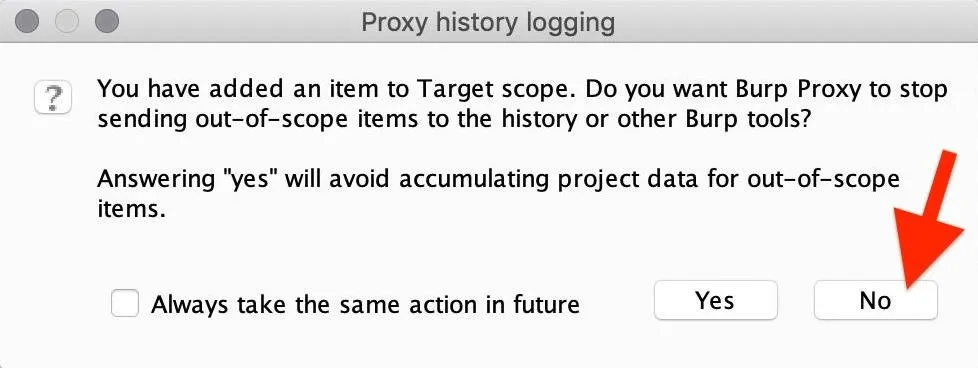
Now, in the "Proxy" tab, click on "Intercept is on" to disable it (we no longer need it), and the Gruyere page should finally load in the browser.
The Spider will begin to request a webpage parsing the links for content, requesting links and continuing to repeat this process recursively for every link found on the web app. A site map will be created and be accessible in Burp's "Target" tab.
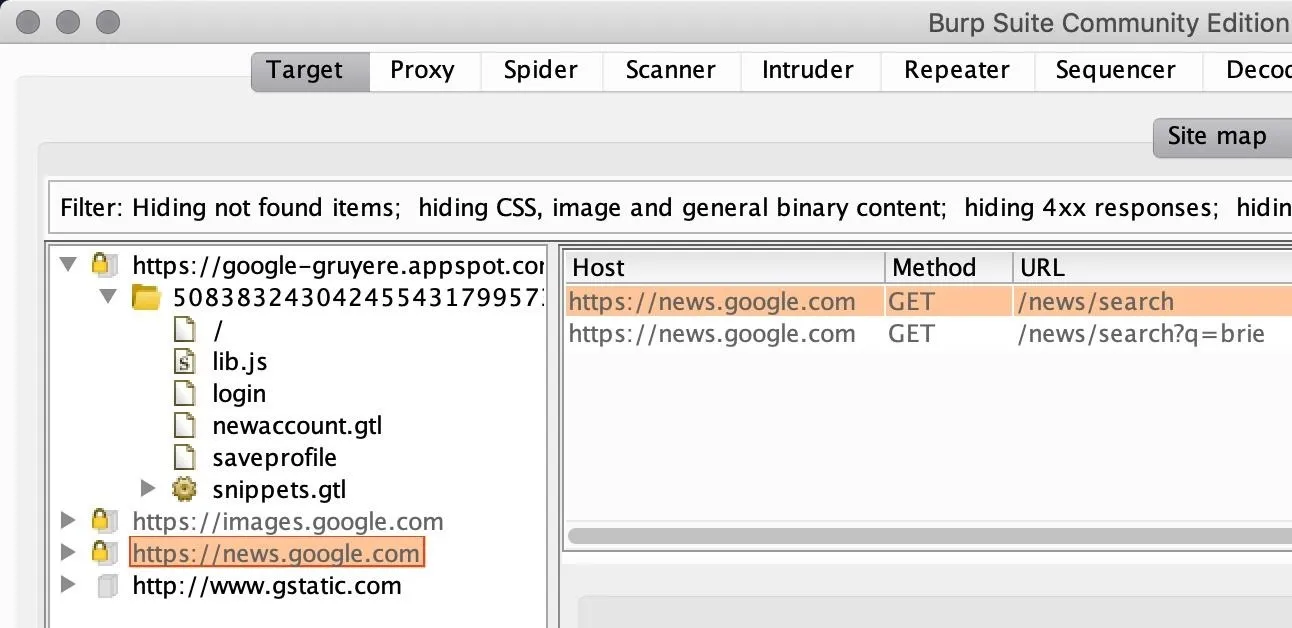
The Spider will also prompt you with form logins to continue recursively mapping the content. Dismiss those prompts in Burp Suite. Instead, we'll create a user right in the browser, then log in using from there to get a better picture of the functionalities available in the user home page.
Discover Functionalities in the Web App
While the Spider is actively running, discovering content and parsing every page you visit, it's time to explore what functionalities a user has access to in the web app. To do so, you must first create an account, so hit "Sign up," and create an account. The goal is to manually explore the web app as a regular user would while, in the background, you're running Burp's Spider to gather all paths you're visiting.
Find a Way to Backtrack to the Parent Directory
Once you have a user account and have logged in, you'll be greeted by a user interface with a navigation bar to do things such as create snippets, view snippets, and upload files. In this tutorial, we'll be focusing on the "Upload" file functionality of the web app since that is where we can find a path traversal vulnerability to use for code execution.
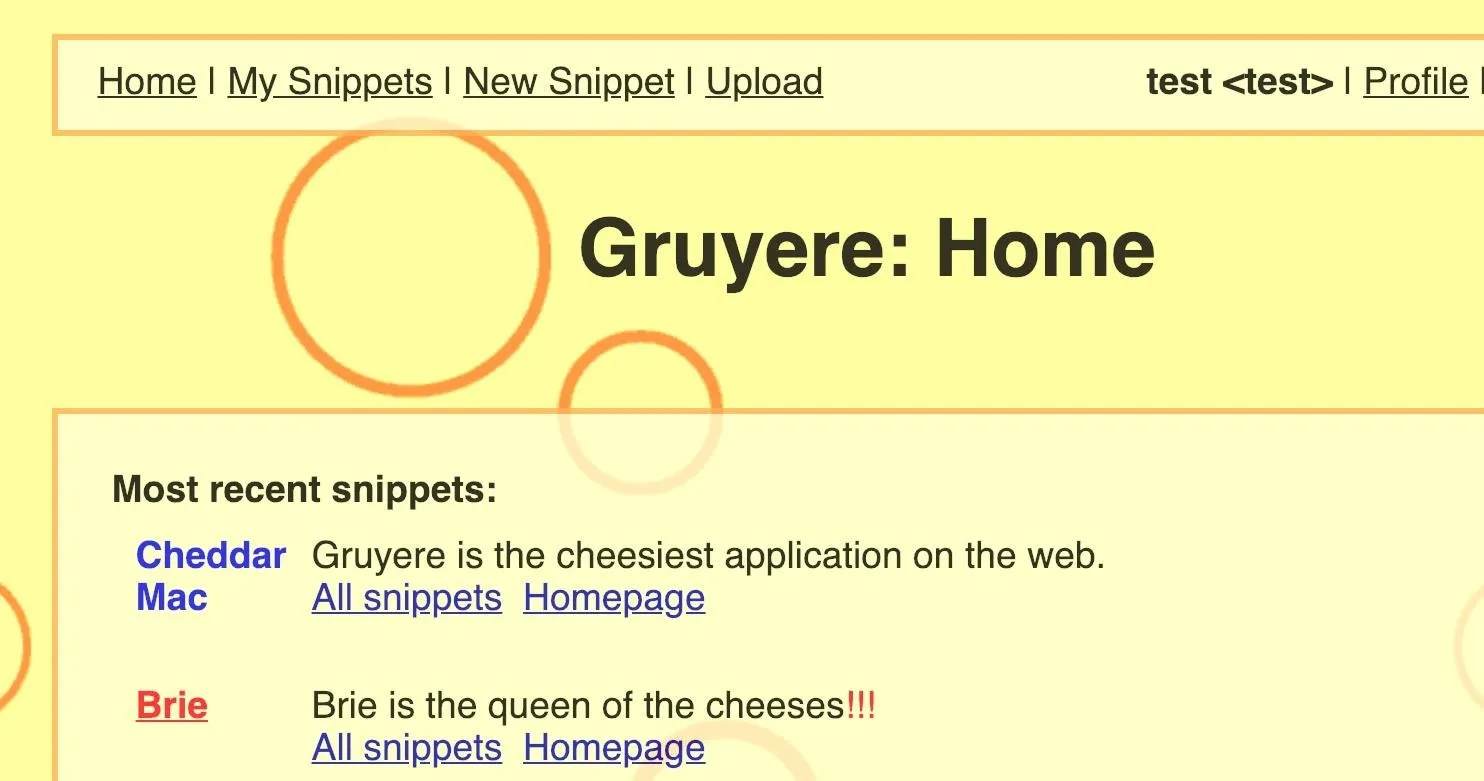
Click on "Upload," then upload any file you want to the application. In my case, I uploaded a JPG image of a cat. Gruyere makes this file accessible at the path that follows this basic naming convention:
site.com/username/fileYou can view the link to your uploaded file next to "File accessible at."

Copy and paste the file link in the URL bar of your browser. This is when you can begin messing around with it to check for a path traversal vulnerability. Type ../secretfile after the file's URL, as shown below. If the URL doesn't end in a / (slash), add that before ../secretfile.
https://google-gruyere.appspot.com/611736743737267028246619854335969477478/test/cat.jpg/../secretfileAfter hitting Enter, an error should appear because the secret file cannot be found in the current directory, Now, try to backtrack into the parent directory of the app with site.com/username/secretfile.
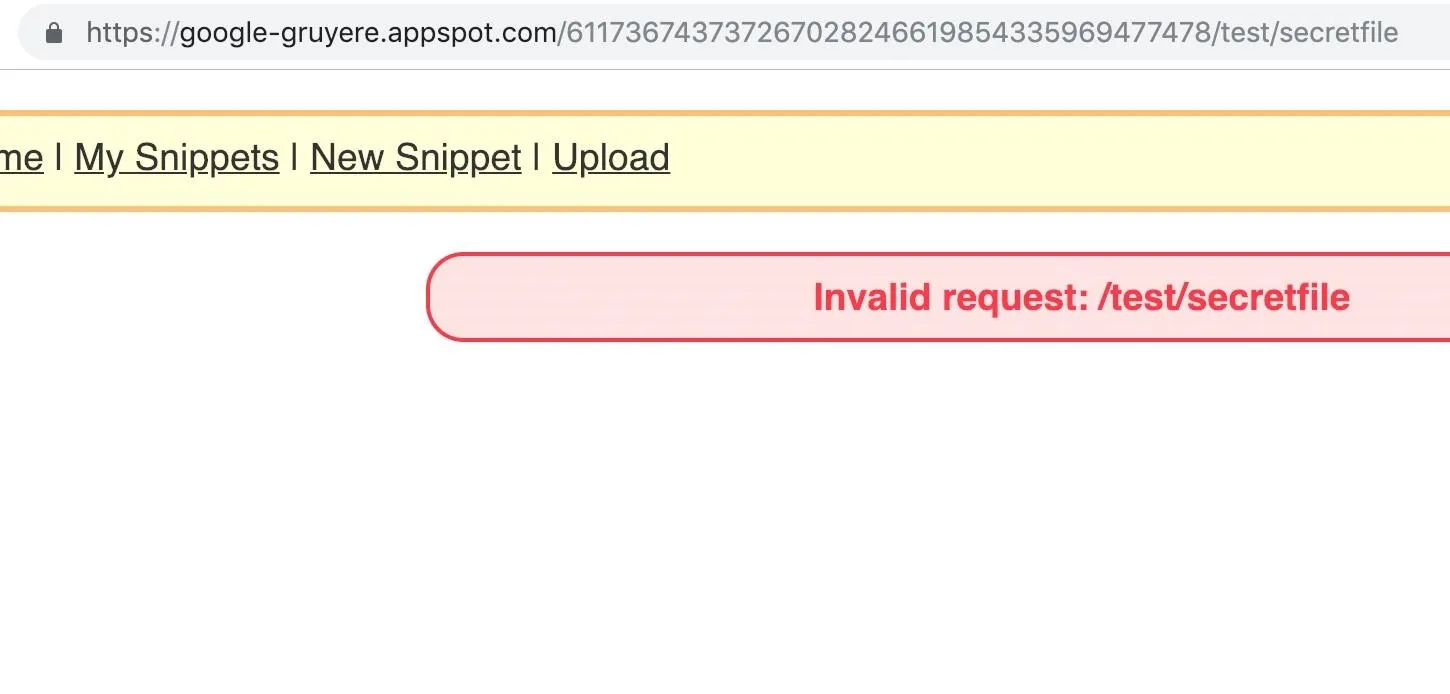
This reveals that the application is omitting the ../ characters to execute and traverse the directories. On some web apps, when entering the ../ characters, the app will scrub the characters, not permitting any way to backtrack into parent directories.
Exploiting File Uploads with a Path Traversal
Making uploaded content available through username/file and allowing users to traverse the directory using ../ characters makes for the perfect candidate for a path traversal vulnerability.
Since the web app is executing the ../ functionality to allow users to escape back into parent directories — a path traversal in the file upload function — it's possible an attacker can replace a file important to the web application infrastructure with their own.
Depending on the file uploaded, a path traversal can turn into code execution. To know what kind of file to upload to trigger a code execution, let's check back with the Spider to see how it's mapped the web app.
Analyze the Source Code in Important Files
Go back to Burp, and check the "Site map" tab in the "Target" section. The Spider should have parsed a lot of paths as you were manually navigating the web app. A very interesting "code" directory will be there, with a file named "gruyere.py," as well as many other Python and GTL files, as shown in the screenshot below.
Notice in the "resources" directory how some of the GTL files also are named after functionality seen in the user navigation bar once logged into Gruyere as a user. So these files "login.gtl," "newsnippet.gtl," and "upload.gtl" are not random files — they are the files with the code that enables users to log in, create snippets, and upload files in Google Gruyere, respectively.
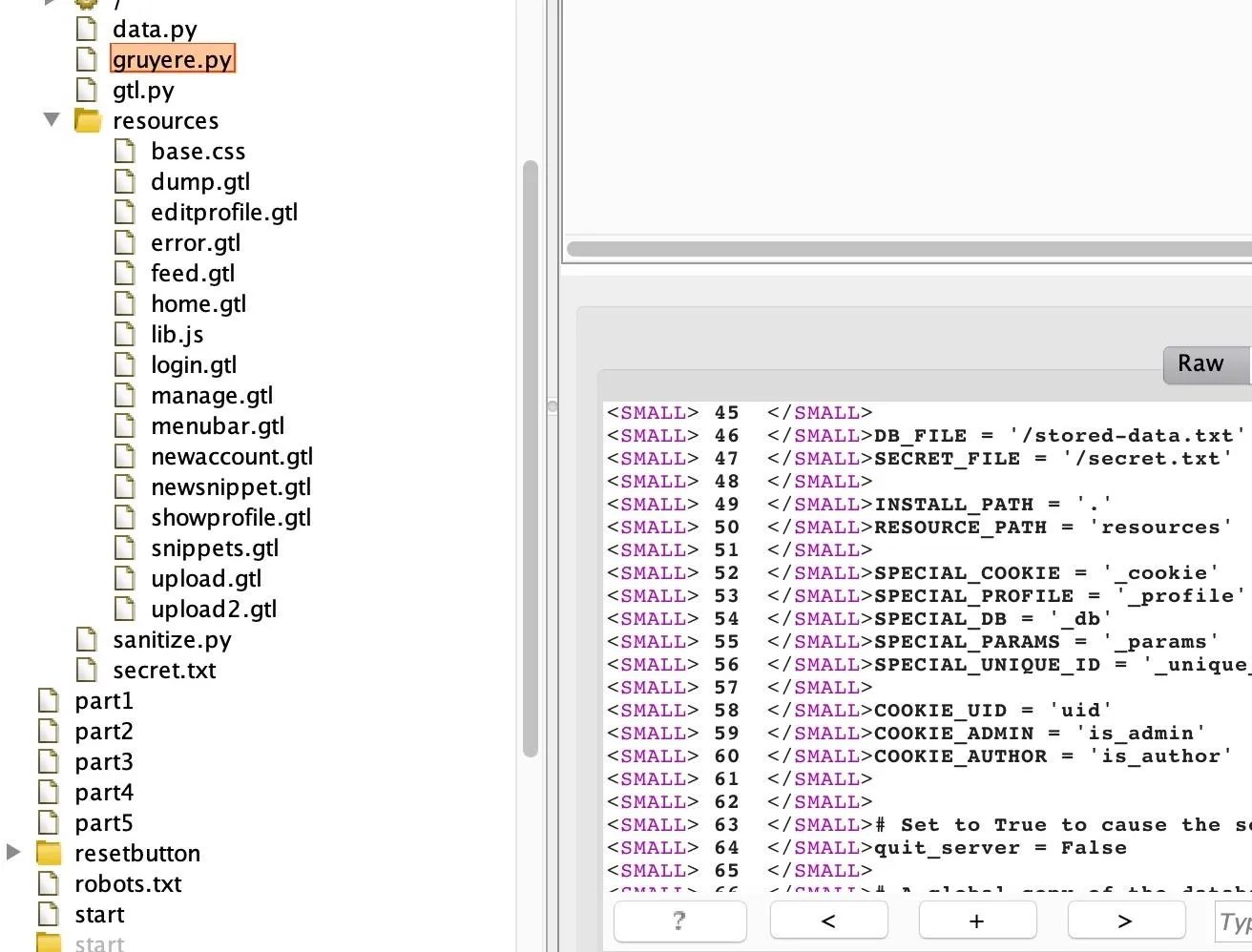
Reading through the Python file "gruyere.py," shown in the image below, notice there is logic built into the application to restart the server with a while loop. The while loop will repeat to handle requests until the condition of quit_server is true, which is met when the user navigates to /quitserver.
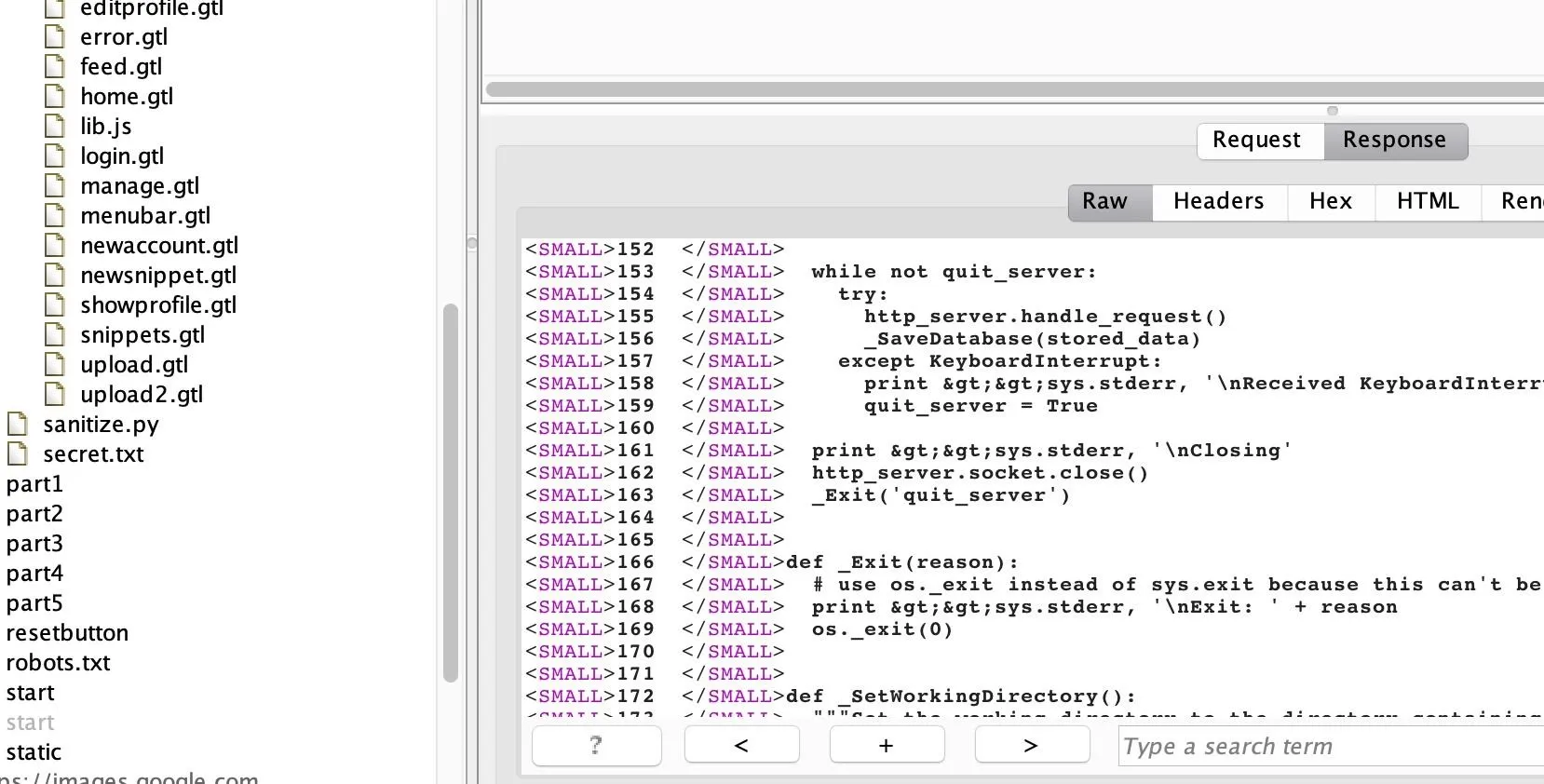
Another interesting Python file discovered is "gtl.py." Reading through its code, it seems as if it's the Python file which builds the GTL templating language for the files that use the .gtl extension. This can be found by reading the beginning of the multiline comment which start with a triple-double quotes (""") in Python reading: Gruyere Template Language part of Gruyere, a web application with holes.
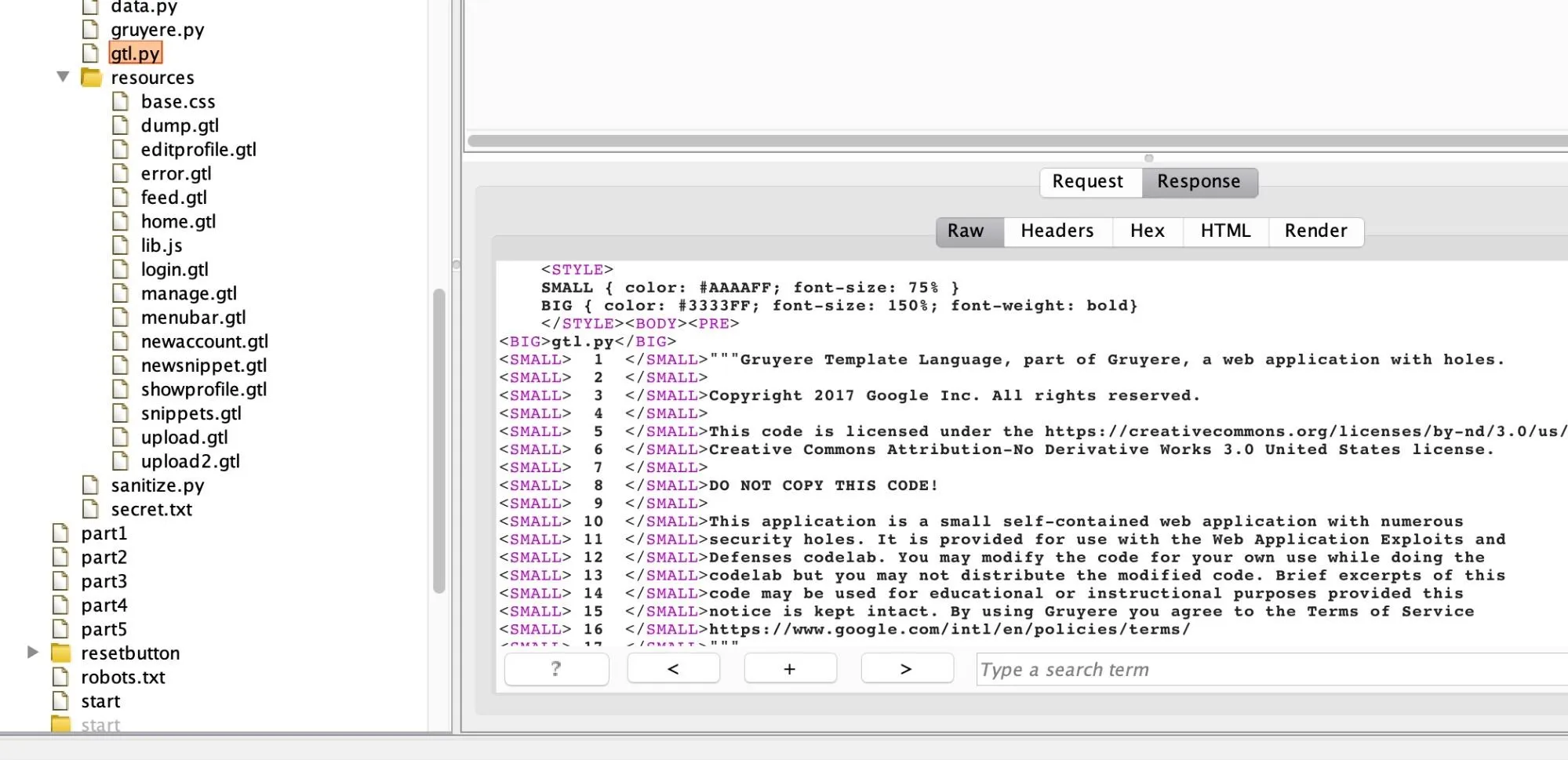
With the files just discovered, what we know so far is Gruyere is a web app which uses a templating language called GTL. The templating language is built by the Python file called "gtl.py" for all the logic of the files ending in .gtl.
Thinking like an attacker, if we could replace the "gtl.py" file with our own, we can rewrite the site's infrastructure and thus own the application. We already discovered that the file upload functionality is vulnerable to a path traversal attack. So if we wanted to replace the "gtl.py" file, we could leverage the file upload functionality by creating our own "gtl.py" file and name it ../gtl.py.
Note that creating files and naming them with characters such as ../ will throw an error on both Windows and macOS. This can be circumvented by creating a user called .. (dot dot) on Gruyere. Then, from the account of the .. user, upload our own "gtl.py," and restart the web application by navigating to /quitserver in the URL bar. If you recall, we discovered /quitserver when the Spider found the "gruyere.py" file.
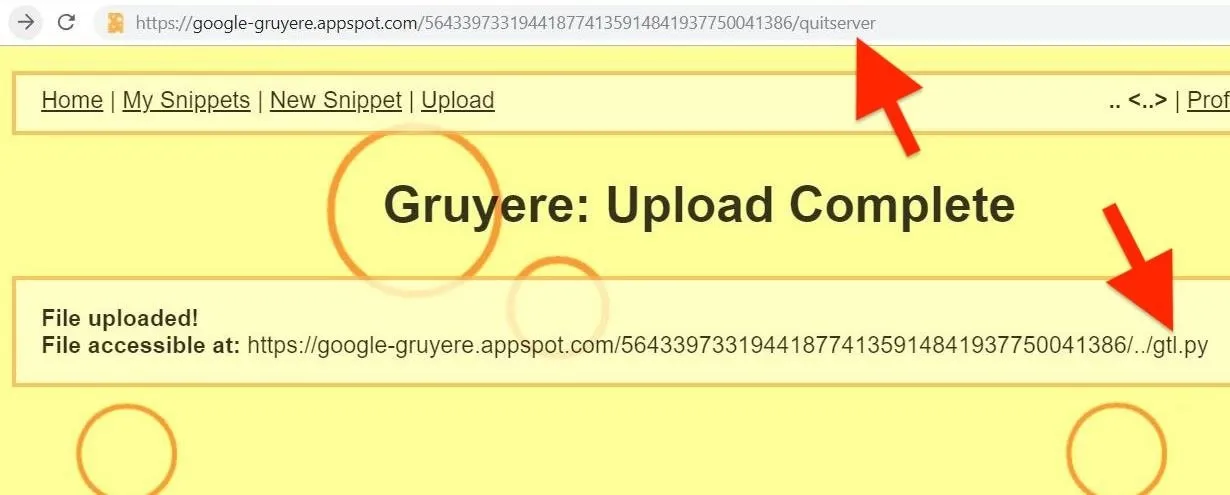
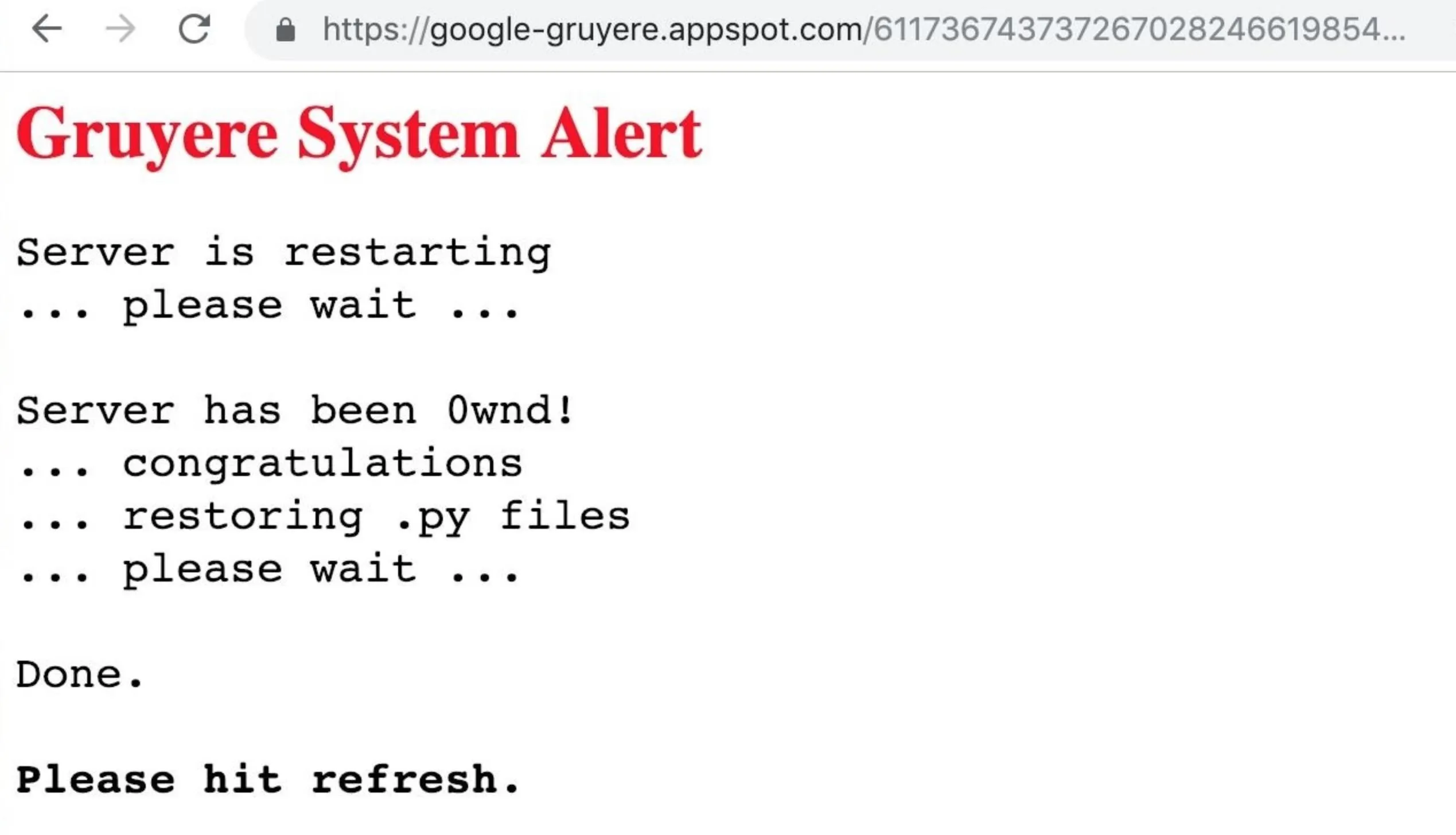
Since Gruyere is a purposely vulnerable web application, the server-owned warning "Gruyere System Alert" should appear, saying that the server is restarting and has been "0wnd."
Real-World Code Executions Will Be a Lot Worse
A real-world scenario of successful code execution would cause a lot more damage. For example, the recent news about the remote code execution found in the package manager which is used to update and install tools used by Debian, Ubuntu, and other popular GNU-Linux distributions.
The RCE attack discovered in January 2019 allows adversaries to issue man-in-the-middle attacks and execute arbitrary code as the root user (which is the user with the highest privileges in GNU-Linux) on any machine. Having a random attacker able to access your computer as the root user would cause havoc, as they can install any file on the system.
Preventing This from Happening
Ways to prevent a path traversal vulnerability in a file upload is to deal with the path traversal vulnerability, then the unrestricted file upload.
For example, to prevent a path traversal, a web app should avoid dynamically reading files based on user input. Second, to prevent a malicious file upload, having a strict whitelist of what type of content, file types, and names are allowed to be uploaded.
Gruyere allowed users to upload a file with the .py extension for a Python file. However, a whitelist preventing Python, JavaScript, and PHP file names from being uploaded, as well as checking for double extension file names, in case an attacker uses a code.py.jpg extension, can make it more difficult for an attacker to upload arbitrary code files to the server.
- Follow Null Byte on Twitter, Flipboard, and YouTube
- Sign up for Null Byte's weekly newsletter
- Follow WonderHowTo on Facebook, Twitter, Pinterest, and Flipboard
Cover image, screenshots, and GIFs by Ginsa0x8/Null Byte




















Comments
Be the first, drop a comment!