




Before I continue with a topic on strings, we first require some fundamental understanding of how memory works, i.e. what it is, how data looks in memory, etc. as this is crucial when we are analyzing vulnerabilities and exploitation. I highly suggest that your mind is clear and focused when reading the following article because it may prove to be confusing. Also, if you do not understand something, please verify all of your doubts, otherwise you may not completely understand when we touch on buffer overflows. I will do my part and try to clearly explain the content.
Basics of Memory
Here is a generalized representation of what memory looks like.
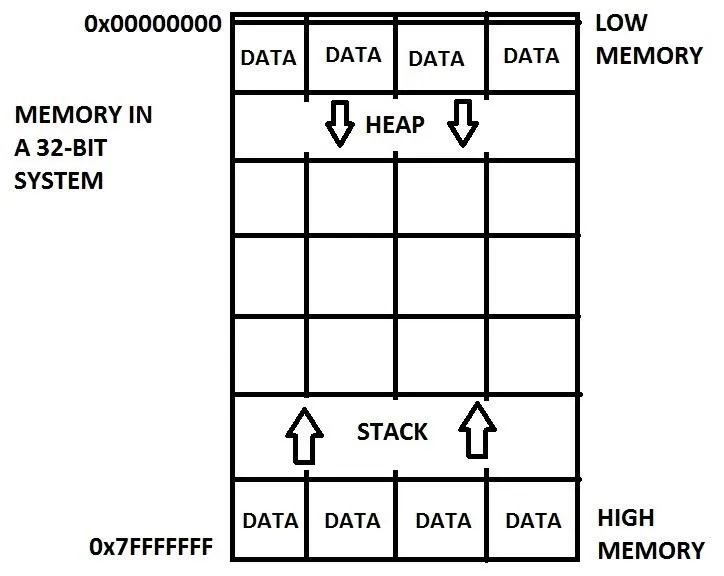
Low memory is located at the top and high memory is located at the bottom. Sometimes memory is depicted as the other way around with low memory at the bottom but we will be using this version throughout the course. As you can see, there is data on both ends of memory. At the low end, there is something called the "Heap" which we will not discuss now. At the high end, there is something called the "Stack" which is typically where the program data is stored such as functions and local variables. Notice that each end grows towards the middle. This is to maintain maximum space for each section. It sort of looks like a huge array, well, because it kind of is a huge array. How convenient! We've already done arrays! Each box is like an element, but we do not refer to them as elements. Instead, we call them memory addresses, like how your house has an address.
The Stack
As previously stated, the stack contains program data such as functions and local variables. We are going to discuss how variables are stored on the stack but first, we must know some details about the stack.
The stack is a "last in, first out" (LIFO) system. A good comparison would be a Pez dispenser where the last item you put in has to be the first to come out. In the CPU, registers EBP (Base Pointer) and ESP (Stack Pointer) maintain the organization of the stack where EBP points at the base of the stack and the ESP register points to the top. We will be using the ESP register to see what data in memory looks like.
Are you ready? Let's do this.
Example Code

We have declared two variables, an int and a char array. For the following memory analysis, I will be using GNU's GDB (debugger). The flags which I used with GCC to build my program will be explained now:
- -m32 - build a 32-bit executable (I am on 64-bit so I need this)
- -gdwarf-2 - build for GNU's GDB debugging
Memory Analysis
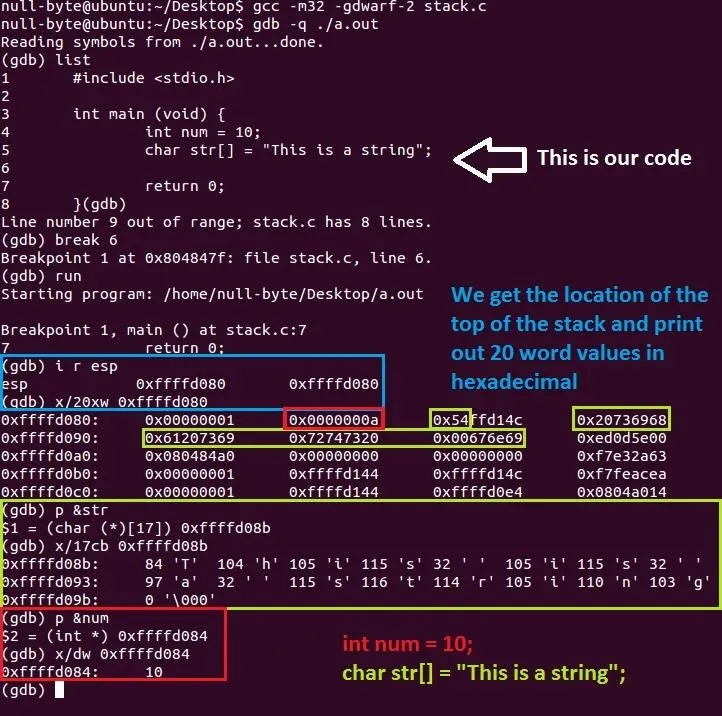
Okay, wow! A lot to take in at a single moment but don't worry, we will go through it all. Remember, if anything is unclear, ask someone for help!
Some prior knowledge before starting:
- A "word" is a term used to describe a size of 32 bits, or 4 bytes.
- Addresses in memory are represented as hexadecimal values.
Let's begin in the blue section. As I have said above in the description of the stack, the ESP register points to the top of the stack and since our data is stacked on top of each other like plates, we can see our variables if we look far enough. Note that the top of the stack is lower in memory (lower value) than the bottom (0xffffd080 < 0xffffd0c0). We can now locate our variables.
Moving on to the red section, we can see a 0x0000000a which is hexadecimal for the decimal 10. I have printed it out (for you to see clearly) as a decimal in the size of a word since it is appropriate for an int data type.
Onto the green section, if you look at the stack, you can see the "0x54" part at the front instead of the end but it is actually the end of that data block. Confused yet? The "0x54" value is hexadecimal for the letter "T" but why didn't I include the rest of that block? Okay, this is because of "endianness" but I will not talk about it now. The green boxed values are the characters of the string where two numbers and/or letters represent one byte (or a char). How you read these blocks of hexadecimals is a bit funny. The data in each block starts at the right hand side and you read it backwards but for the entire green area, you read it normally from left to right. Try decoding the hex values and write them down, you will see what I mean. I will explain hexadecimals in another tutorial.
In the bigger green box, I have located the address of the string (p &str) and then printed out 17 characters in the size of bytes (x/17cb 0xffffd0b8) and now it's human readable and easier on your eyes. Notice that the buffer is 17 bytes which includes the null terminator (\0). The number on the left is the decimal value of the corresponding letter on the right. But wait, characters are numbers? Yes, they are! Computers don't understand what letters are... What do you think they are, humans? If you want something to clear this up, head over to AsciiTable for a table of different representations for characters.
Conclusion
Okay, I think that's enough content for one tutorial! Hope you haven't decided to give up yet! Everything will be made clear when I go over them in future tutorials so just relax. Take a break if you're mentally exhausted from all of this random spewage of nonsense. But hey, at least we can now go over strings and buffers now! I know you've been waiting for a while! Stay tuned!
dtm.




















Comments
Be the first, drop a comment!