
Hi, everyone
So, a lot of people these days are getting into trouble for crawling the databases they are not supposed to even though they are public information, how about that? You can look at it online but not store it on your computer. It's like i'll tell you my password but you should not remember it.
Now, I was getting bored and thought of crawling one such online database, lets call it http://www.hackabledatabase.com
Step 1: Looking Around the Web-Page
These usually require you to enter some data in some text boxes and click search button and it throws out or redirects you to another page.
Lets say, we want to search for someone by the name 'null-byte'. So we enter the name in the name box and click search. the website redirects us to http://www.hackabledatabase.com/null-byte

Where it shows his name and his hacking skill.
Notice the URL has his name at the end.
This seems interesting! I ask myself what if i put my name at the end?
So i type my name instead of null-byte at the end
http://www.hackabledatabase.com/dragonslayer
WOW! this prints my user data.
Step 2: Bwahahahaa! We Have Our Evil Mind at Work.
Lets say we have now with us a list of 2 million users whose data we want access (some list we got from a friend ;) ) and probably want to store so whenever we want help in some specific hacking skill we can look it up. So instead of searching people and find what their skills are i want to be able to search a skill and find people who can help me out with that.
This seems easy, all I have to do is type their name at the end of the url and fetch the data, just do it 2 million times. (I want to shoot myself in the head).
Step 3: What Do We Really Want and How to Go About It?
We know what we want, the data of the user, but we have a webpage, not an excel sheet, DUH! Lets see how the data is stored on the webpage.
Right click on the name 'dragonslayer' in the webpage and select inspect element.
This opens the developer tab in your browser. You'll see the name 'dragonslayer' is stored in a <div> tag with a class name, here it is "detailedView(underscore) nameText" and if you right click on that <div> tag you'll see an option 'copy XPath'. This is the path to that data in the webpage.
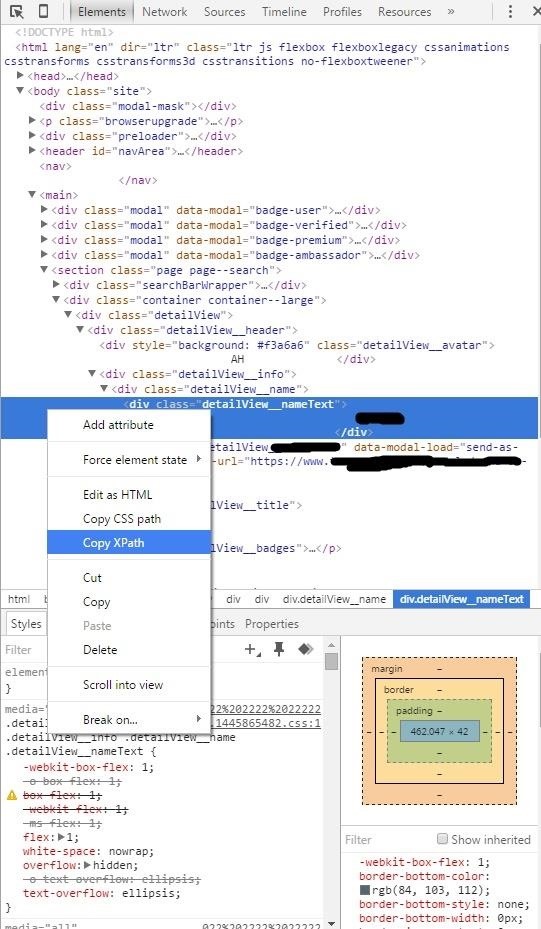
Now, we know where data is stored on the webpage.
This is a teaser for you guys. In my next post we'll look at the python code to do this and possibly setup my website so you can practice there (though it won't have 2 million entries to scrape).

































3 Responses
Good article!
Thanks JEREMIAH PAYNE!
I'm guessing Soupy and Regex is going to be in the next article, good post!
Share Your Thoughts