


Welcome back! In our previous tutorial, we learned how to identify all links from a webpage: our source code looked like this.
You can check it out here: https://null-byte.wonderhowto.com/forum/creating-python-web-crawler-part-2-traveling-new-sites-0175928/
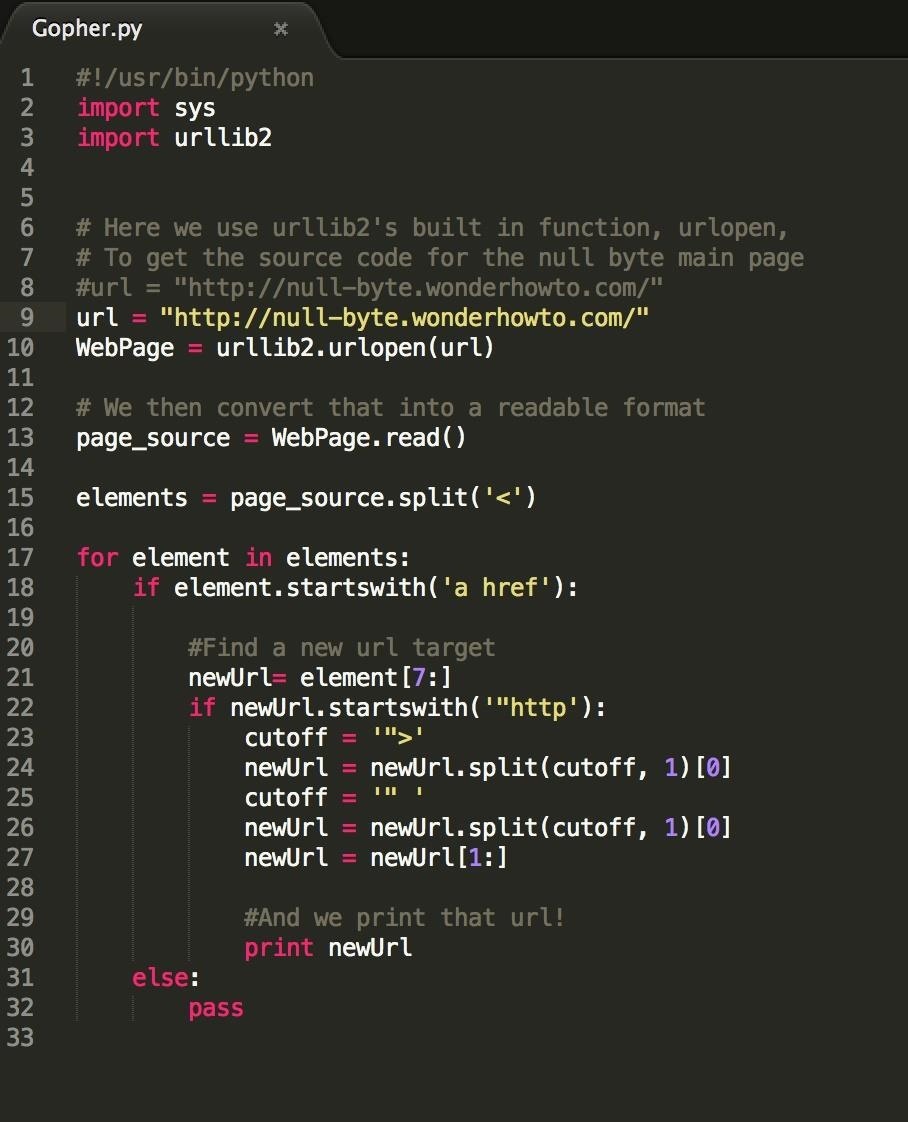
It's pretty cool to be able to view all the embedded links in one page, but this is actually kind of dangerous and unhelpful.
Think about it this way: an average site page will contain realistically 25-750 links. If we were to just open every one of those links and replicate our Web-Crawling process each time, we would likely be increasing our search scope my a magnitude of 100 each iteration of our crawl. Open one web page, open 100 webpages, open 10,000 webpages, open 100,000,000; you get the gist of it. This takes an incredibly long time, wastes your computer resources, and doesn't really accomplish anything useful.
So let's narrow our scope! First things first, lets make sure to never open the same website twice. We can achieve this with a simple list data structure.
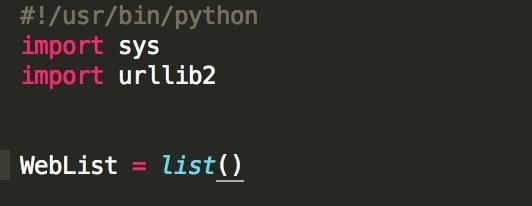
At the top of your program (before you ever even open up a link), create your WebList structure. We will use this to keep track of which websites we have actually visited.
Now, we have to actually keep track of our webpages, and make sure we only visit each once, like so:
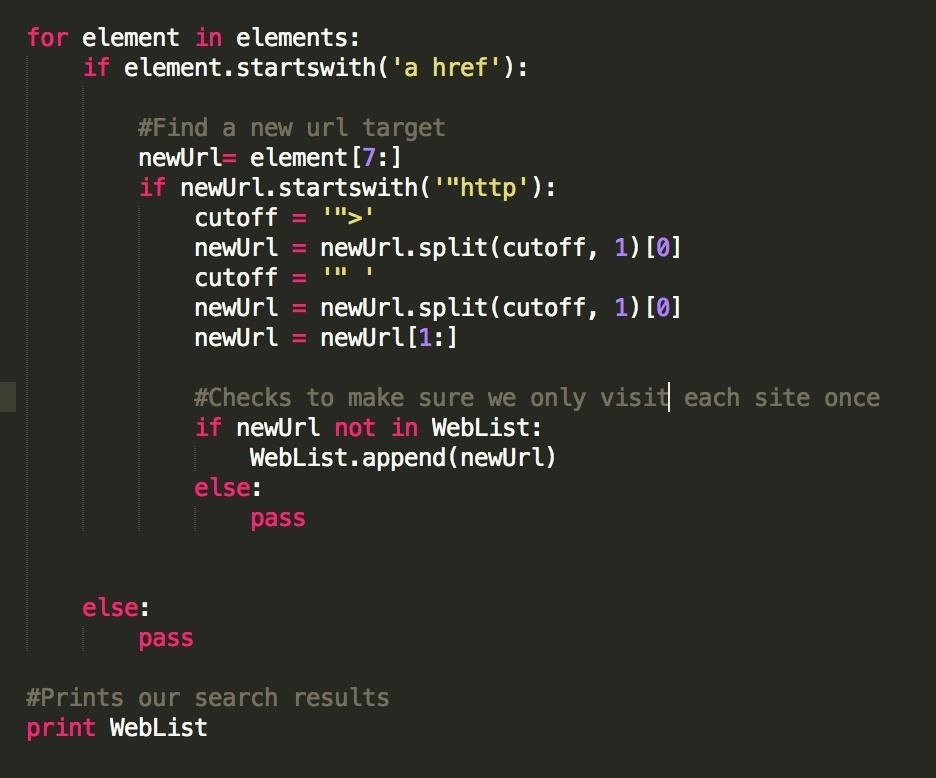
Pay attention to last code block, after '#Checks to make sure we only visit each site once'. Let's break down what we're doing here.
- "if newUrl not in WebList": Our WebList is our list of visited sites, so what we're writing here is, 'if this webpage isn't marked as viewed, do something. Remember, 'newUrl' is the refined version of our link, extracted from each '<a href>' HTML tag.
- "WebList.append(newUrl)": If we haven't visited the webpage, we mark it as viewed by adding it to our WebList. The append() function simply adds a new element to the list, as well as increasing it's size by 1.
- "print WebList": At the end of our program, we print our list and see what websites we visited.
Run your program again, and you'll see a list of all the websites you visited, none of which are repeated.
Keep in mind that you really did just visit all of these websites, your browser just didn't assembly them. You still sent some TCP data packets though, and your IP address can still potentially become logged.
Now comes a new approach to this tutorial, and I'll admit that we're now taking this project in my own personal direction. Making a spider capable of crawling the web is cool and all, but how can we make this a legitimate hacker tool? For the purposes of this tutorial, we will be refining our Web-Crawler to only crawl through a specific site. Why only a specific site? Because it's likely you'll want to be analyzing a specific target.
The next part of this tutorial gets a bit whack, so definitely try to copy exactly what I've written if you want tangible results. Again, we'll be doing some string-manipulation, and this stuff really is the result of trial and error.
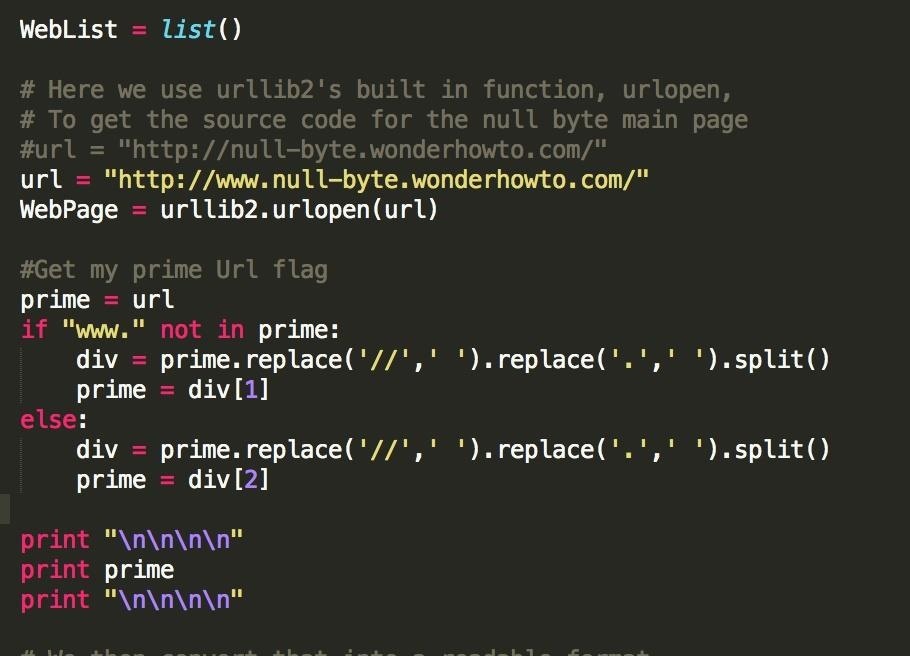
What's going on here, and why?
- "prime = url": I'm copying our original url (our starting point) to a new variable, called prime, so that we can mess around with it a bit.
- "if 'www.' not in prime:": Case 1 where we start our search with http:// or https://
- "else:": Case 2 where we start our search with http://www . or https://www .
- "div = prime.replace('//', ' ').replace('.', ' ').split()": This is where it gets a bit complicated. Basically, what we are saying here, is that our new list/array variable div (div for divided) is the result of taking our url and converting every instance of "//" or "." into an empty space. Hence, our variable prime would now be "https: www null-byte wonderhowto com/", with all the spaces included. Then, with the 'split()' method, we split this string up in every instance of a blank space, and store the results in our div list. Thus, the div variable would look like [https:, www, null-byte, wonderhowto, com/].
- "prime = div[1]" or "prime = div[2]": Here, based on our above mentioned cases, we choose the index of our target keyword, in this case "null-byte", and make that our prime variable.
Go ahead and run the program now, you should see "null-byte" printed at the top, with 5 spaces above and below it.
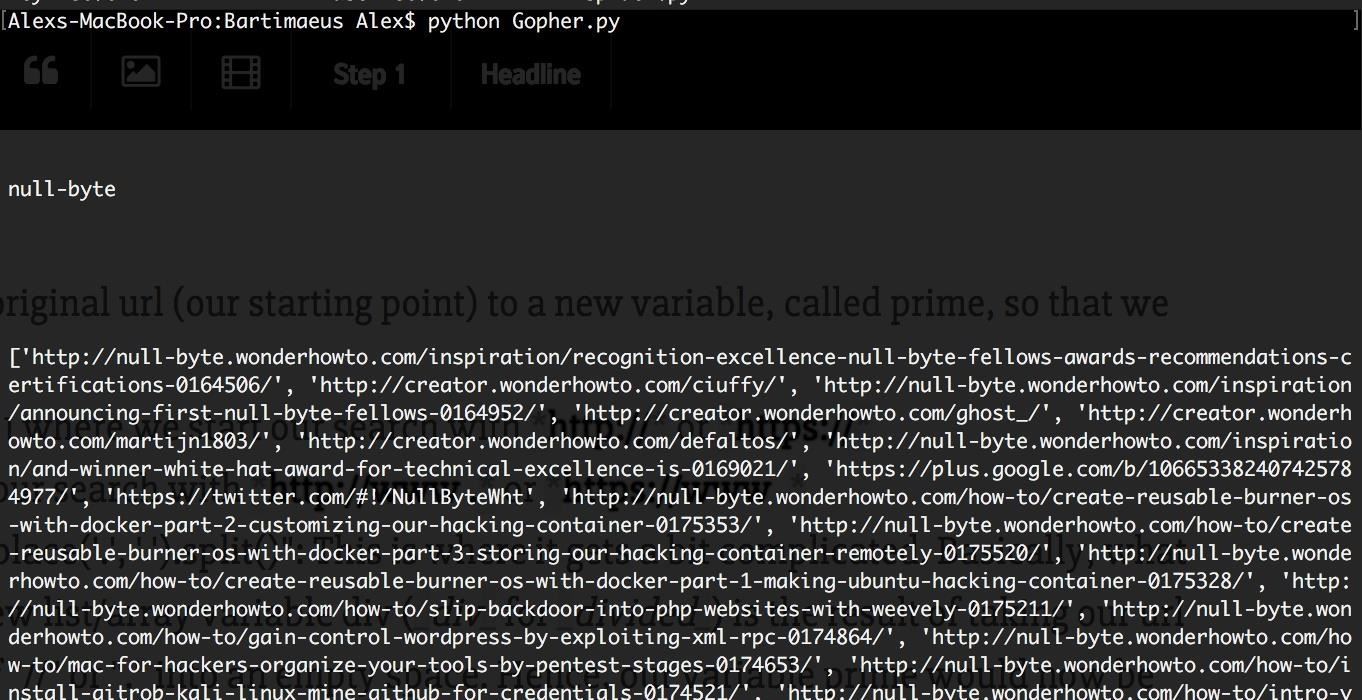
Cool, we have our key word! Now how do we use that information to our advantage?
Well, let's take a step back to where we narrowed our search earlier. We made a check to make sure that we didn't list any links twice, why not make a check to make sure we don't list any links without the "null-byte" keyword? Based on what we've done so far, that's actually pretty easy.
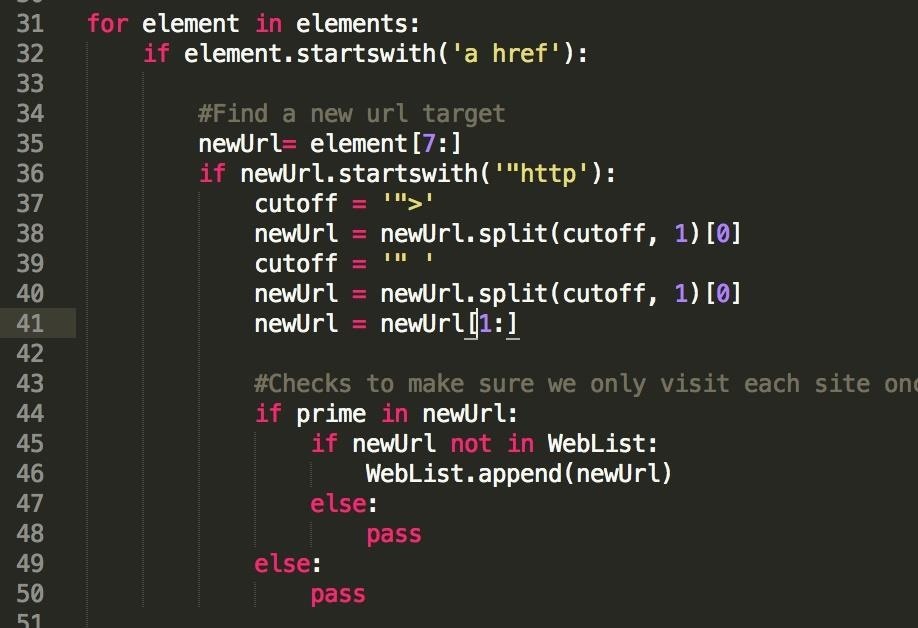
Just add another if/else statement in there on line 44, to see if the url we're scanning actually links to our website.
"if prime in newUrl": pretty much just says, "if our newUrl variable has the word 'null-byte' in it, do this". If you've done programming in some (relatively) lower level languages like Java or C , you'll appreciate how powerful this statement is. You can do really cool stuff really easily with Python, that's why it's awesome!
Anyways, run your Web-Crawler now and you should see that it has a significantly reduced search scope.
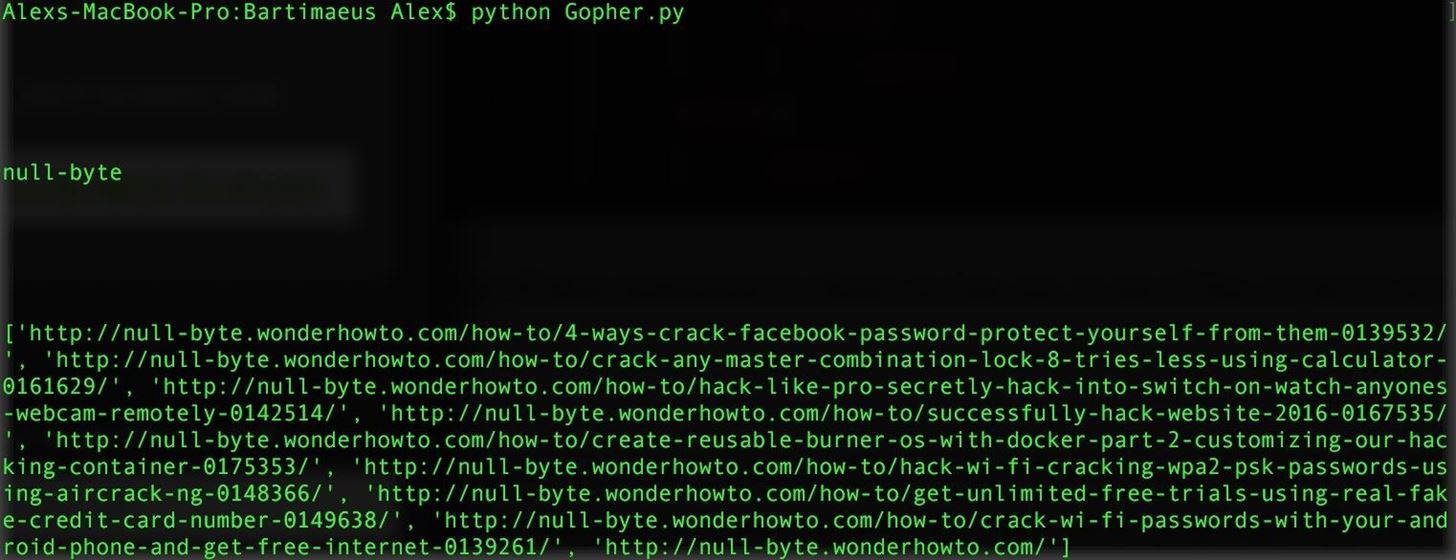
We only opened about 20ish links, which is exactly what we want. We have now specified our spider to only crawl through our target, in this case Null-Byte. Now we can begin to move forward, and actually start to replicate our Web-Crawler to make multiple jumps, without opening up 10,000+ links at once.
A complete view of your source code should look like this:
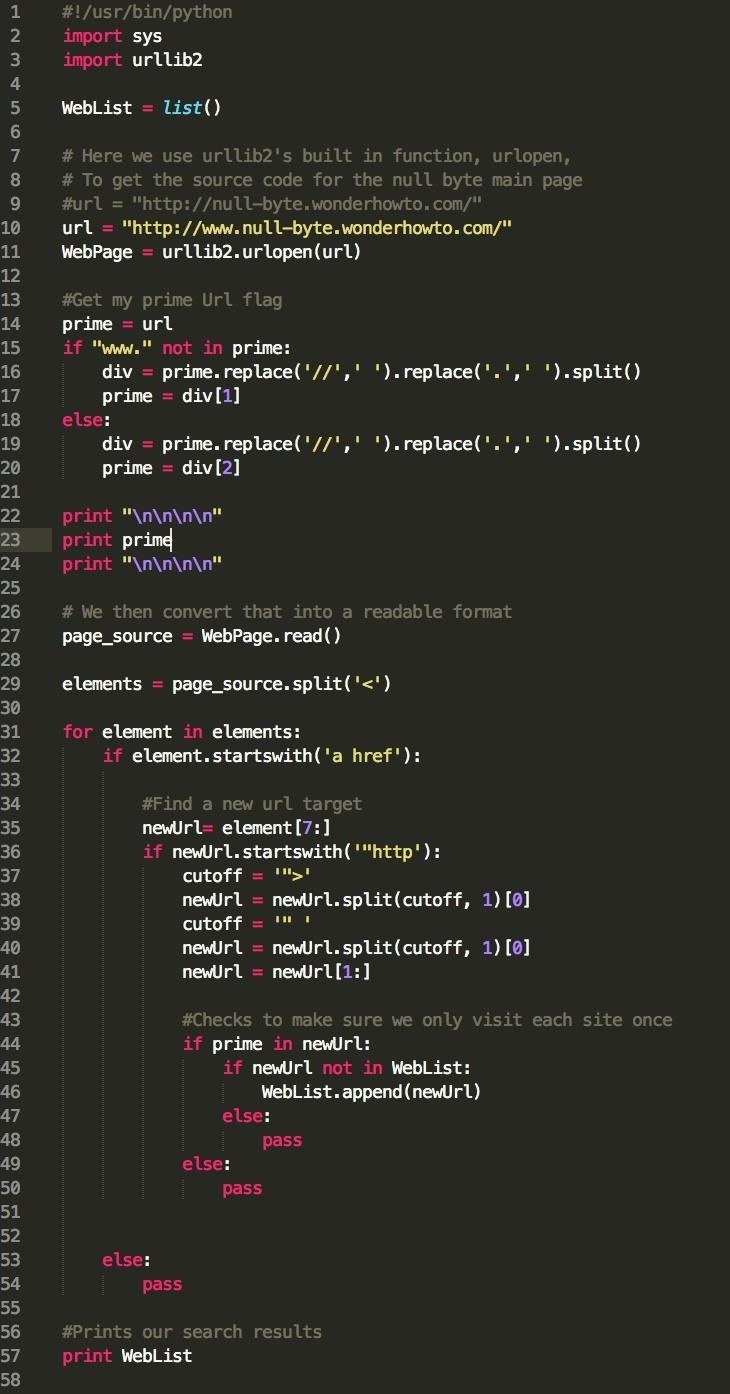
We can run this once and view 20 pages from our target, run it twice and view 400 pages, run it three time and view 8,000 pages, and finally run it 4 times and archive the entire site in under 10 minutes. Cool stuff!
Tune in next time and we'll learn to define our Web-Crawler recursively, so that it can replicate itself on the fly. We've actually already done the hard parts, so the recursion should seem pretty intuitive at this point.
Peace out Null-Byte



































1 Response
Link for part 4?
Share Your Thoughts