

The Hancitor (aka Chanitor) malware is a downloader, which has been around since about 2014 and is usually spread through malspam campaigns. Upon infection, a system with the Hancitor malware sends a beacon to a C2 server. The beacon contains plain-text information about the infected system, but the response contains encoded information.
This article demonstrates how to use Python scripting to decode a Hancitor C2 response.
Step 1: Identify the Encoded Response
This demonstration uses the 1st run PCAP found here. Within the PCAP, follow the TCP stream for the first POST request. We can see the initial POST request to the C2 server, with a long response that looks potentially base64 decoded.
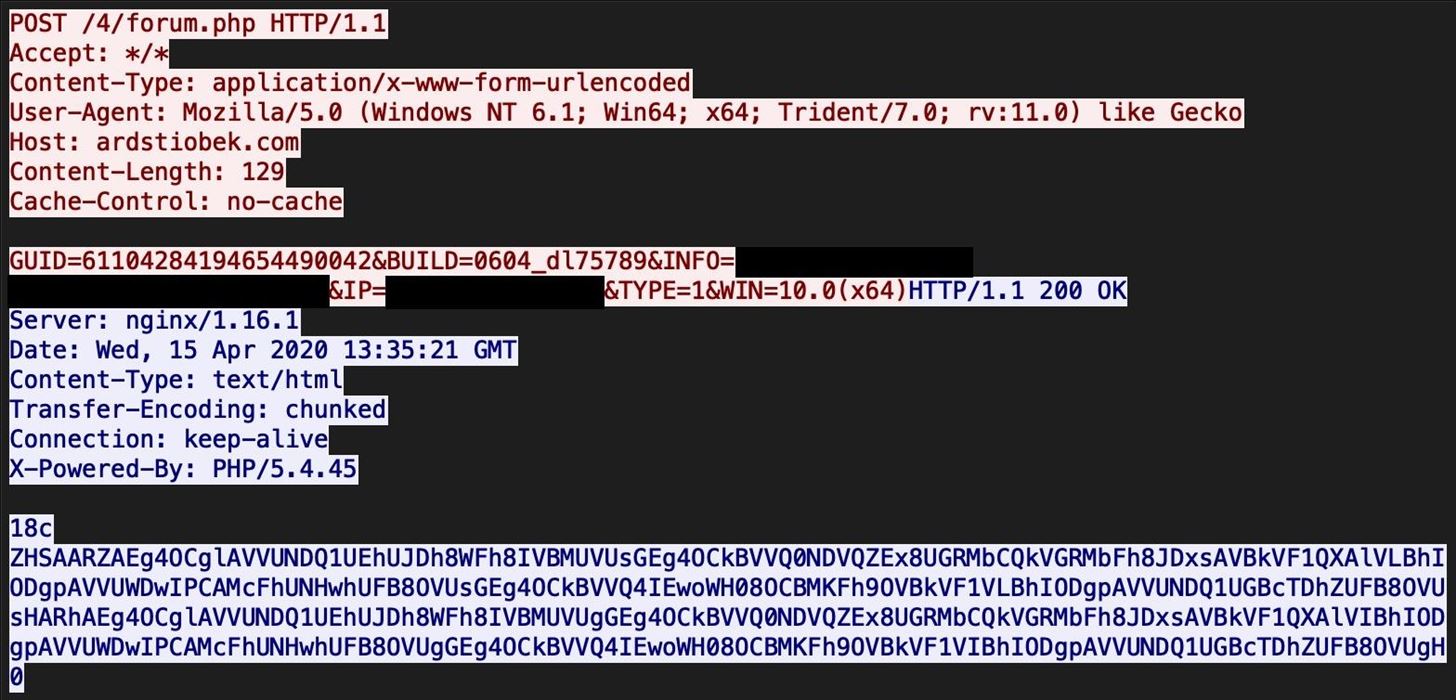
The "18c" in the beginning of the response is simply the hex length of the base64 blob. The "0" at the end signals the end of the payload.
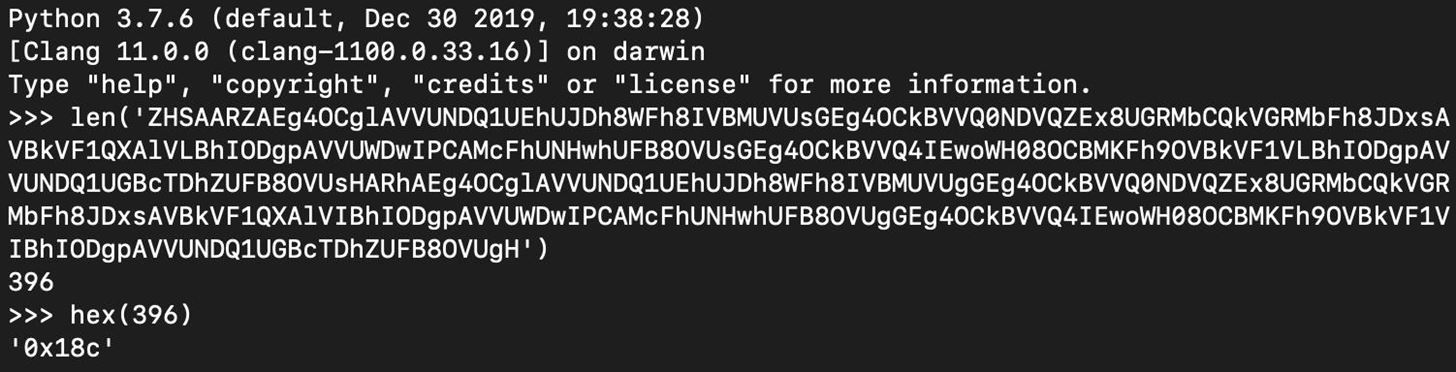
The portion in between "18c" and "0" is the part we need to decode.
Step 2: Decode Base64
The part we need to decode appears to be base64-encoded. We can use the Python base64 module for decoding.
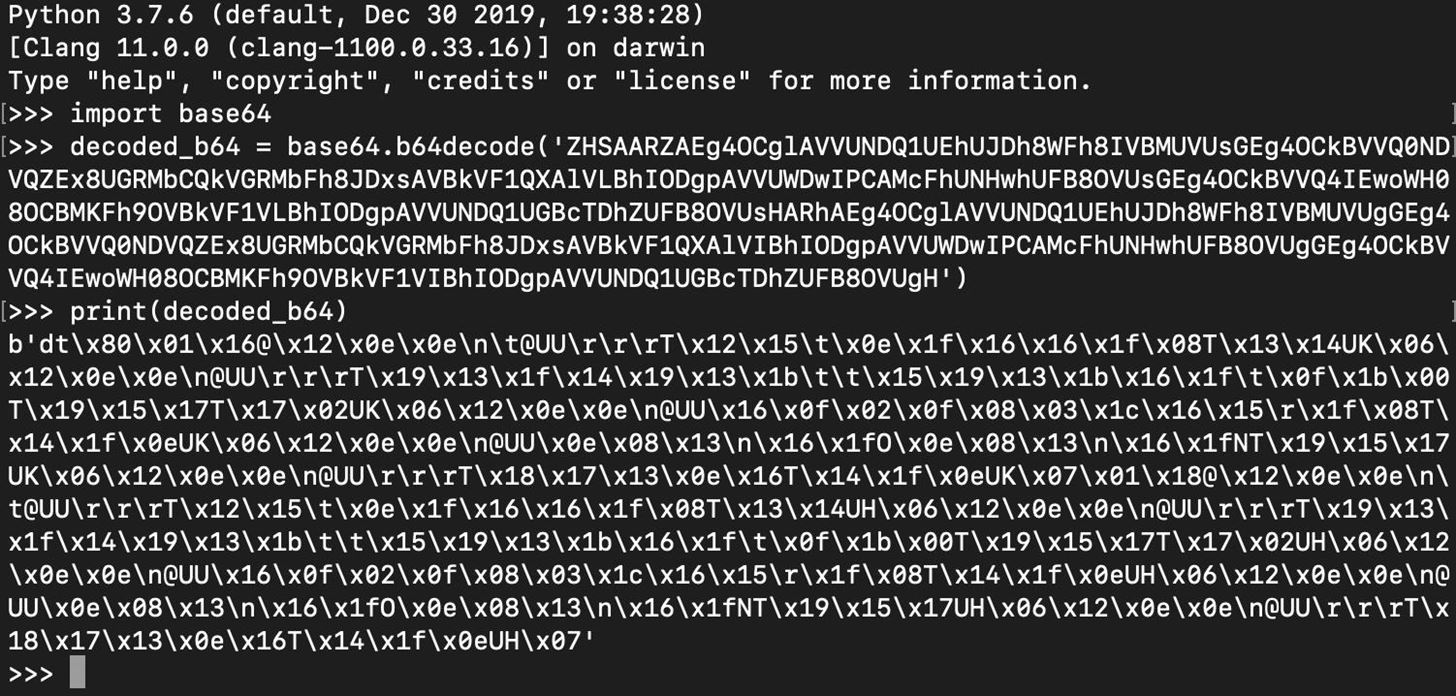
The base64 decoding works, but the result is a bytes object that is not readable.
Step 3: XOR the Result
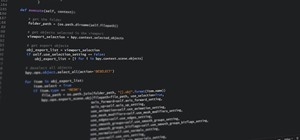
Hancitor has been studied before by many security researchers, and it is well-known that the payload is first XOR'ed with key 0x7a before it is base64-encoded. However, if we did not know this specific information beforehand, we could rely on the general knowledge that XOR'ed data is a pretty common obfuscation technique when dealing with malware, and we could check for a XOR key using Python. The code shown below loops through all one-byte XOR keys from 0x00 to 0xff and XORs them with the decoded base64.

About halfway through the results, we see that key 0x7a contains readable text, so we know this is our key.
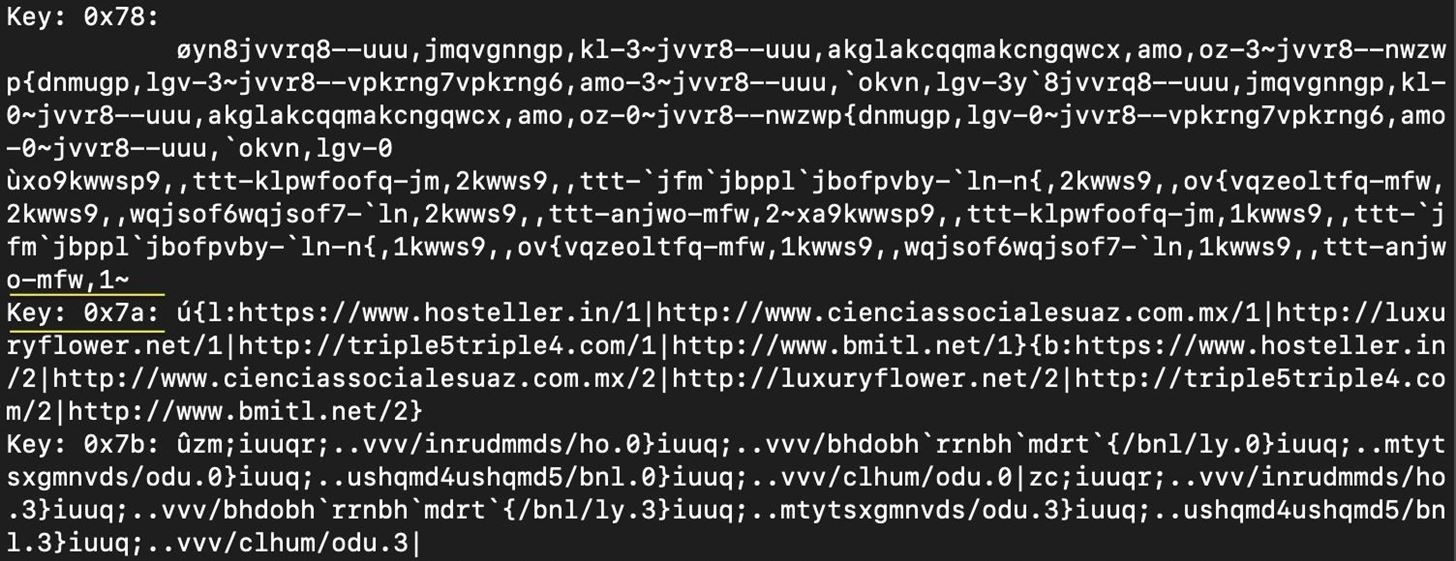
The result for key 0x7a is a list of URLs, which we can deduce are associated with the malware.
Step 4: Extract IOCs
We have successfully decoded the C2 response payload, and it contains a list of URLs. Since these are actionable IOCs (We can do things like incorporate them into security technologies for blocks, use them for hunting, and share them with others), we will extract them into a neat and usable sanitized format so they can be handled safely. We will use the Python re library, which allows us to work with regex.
Using regex, replace http/https with hxxp/hxxps. Then, replace each "." with "[.]". This is a common method to sanitize URLs for safe sharing.
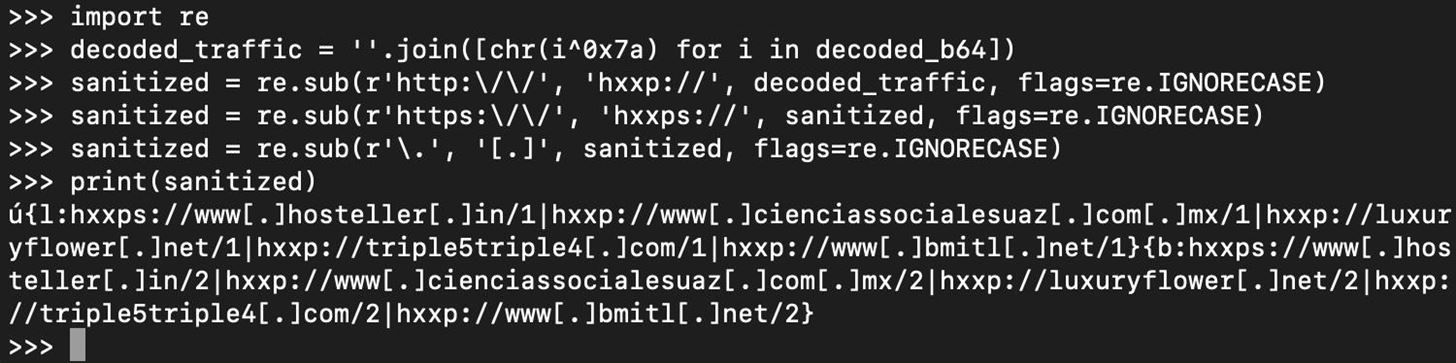
Now, we can again use regex to find all parts of the variable called "sanitized" which contain a match to a URL, so we can display an organized list of the sanitized URLs for sharing and other purposes.
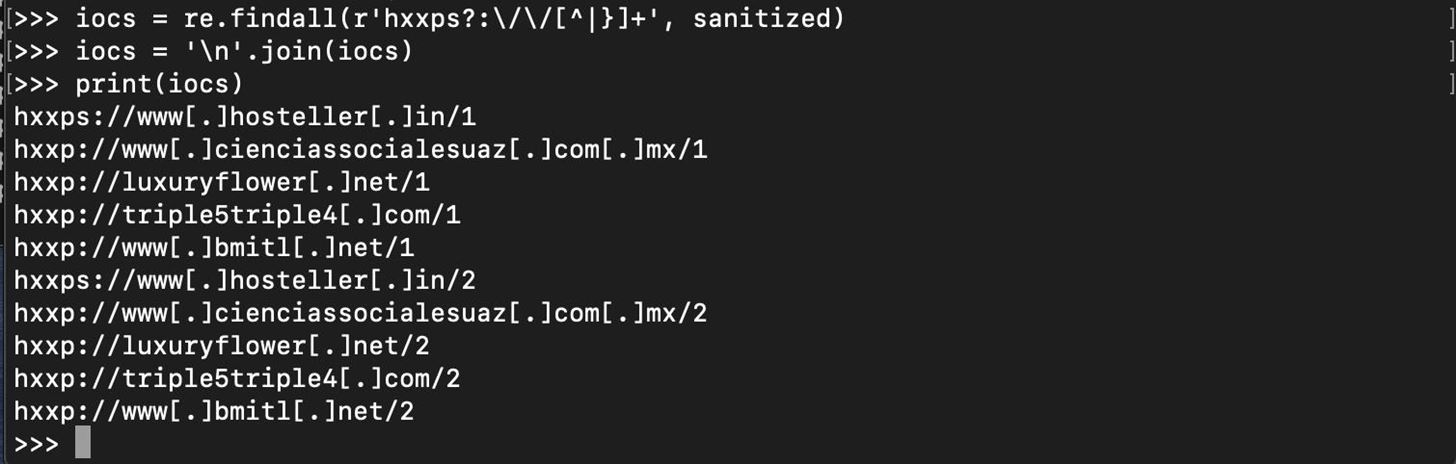
And that's it!
I have also added a Python script to GitHub to handle this decoding if you'd like to go a less manual route:
github.com/fierceoj/triage-tools/tree/master/hancitor_c2































Be the First to Respond
Share Your Thoughts